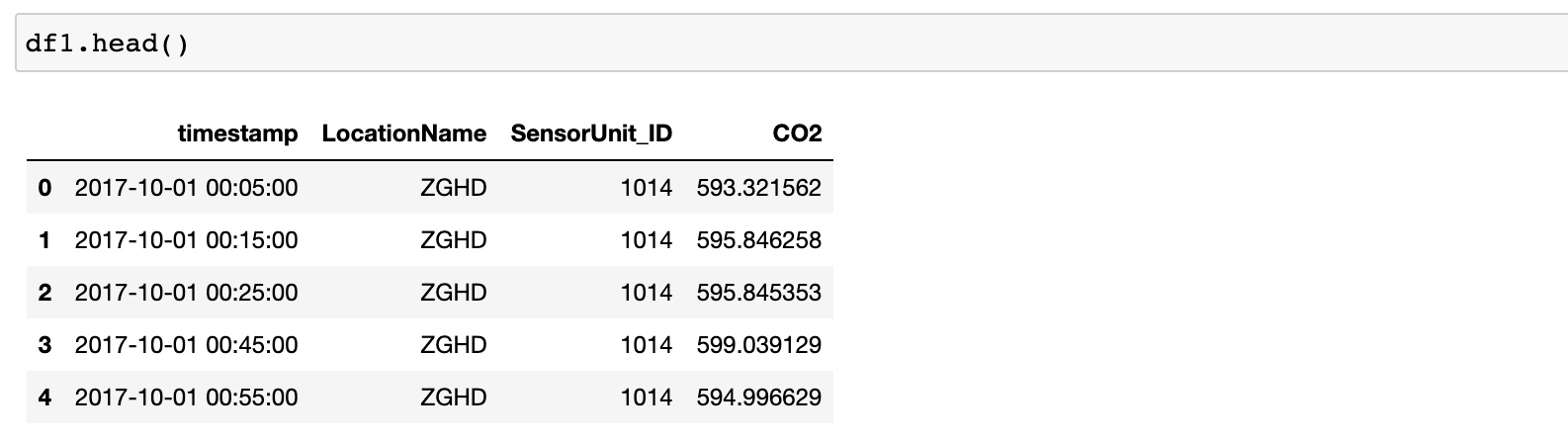
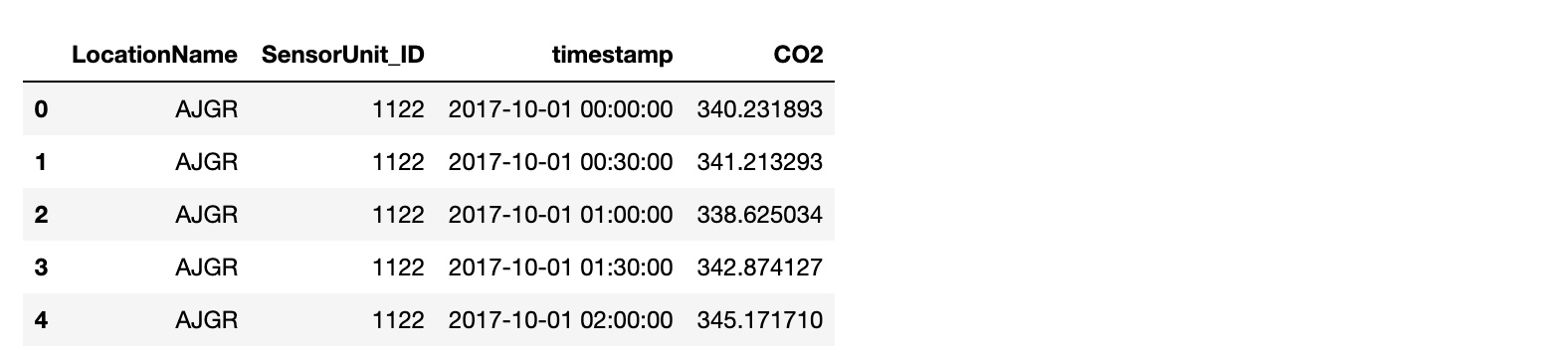
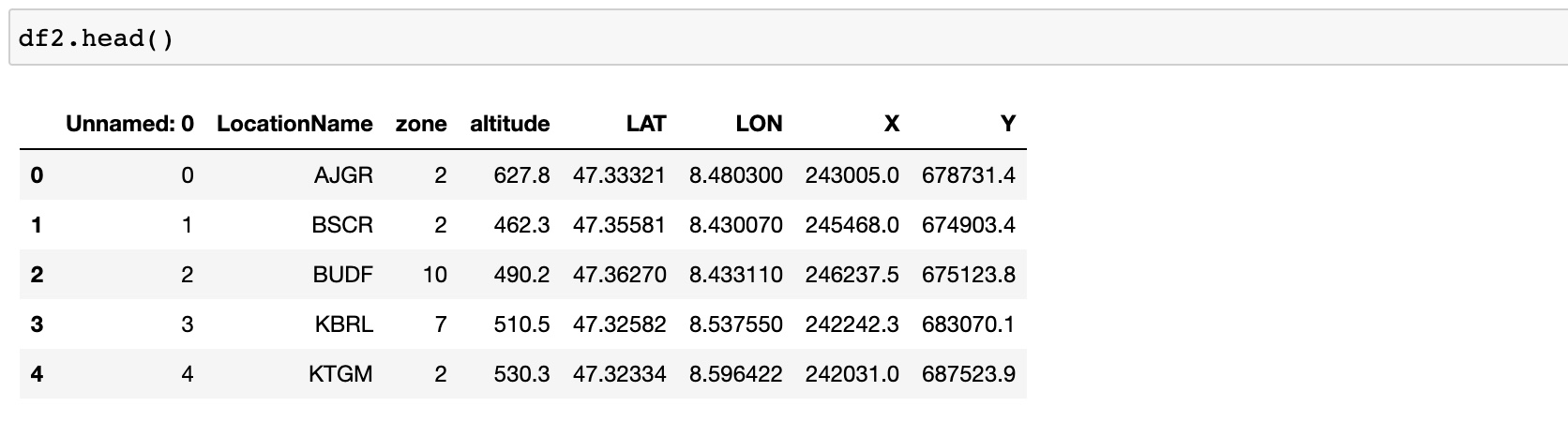
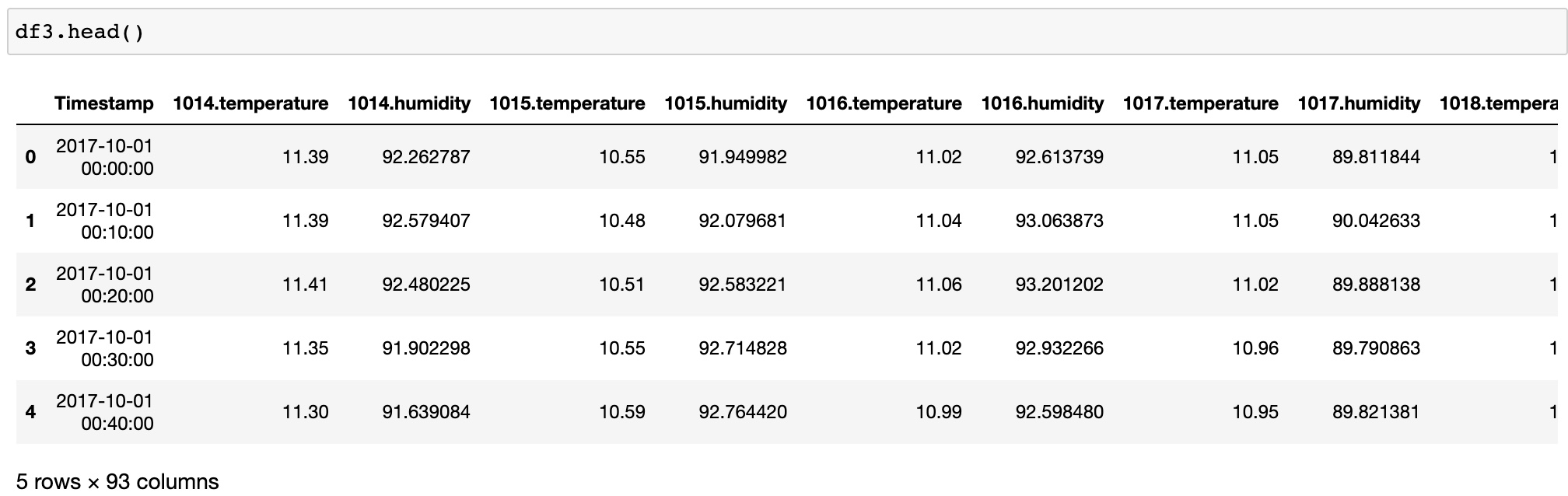
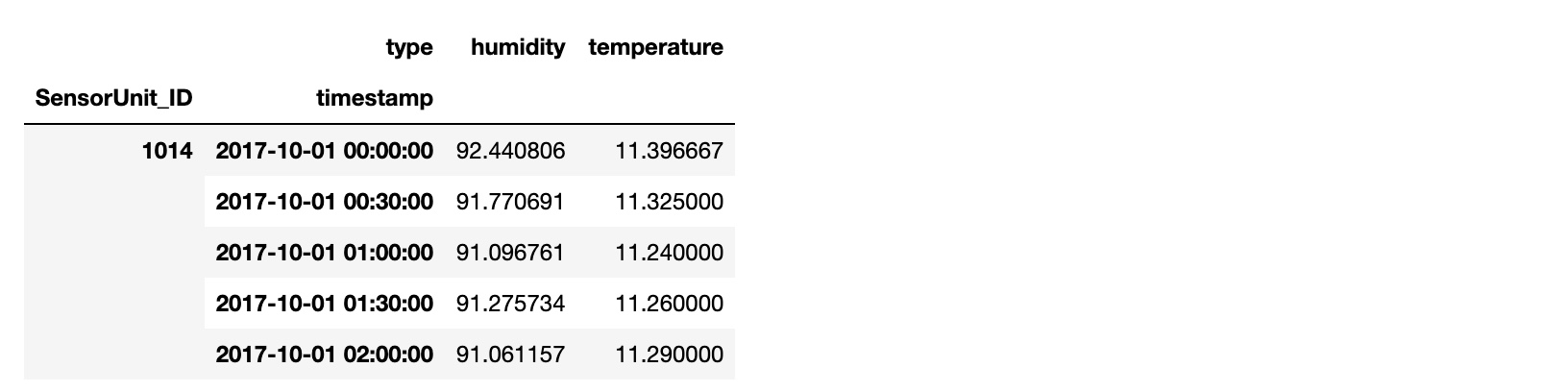
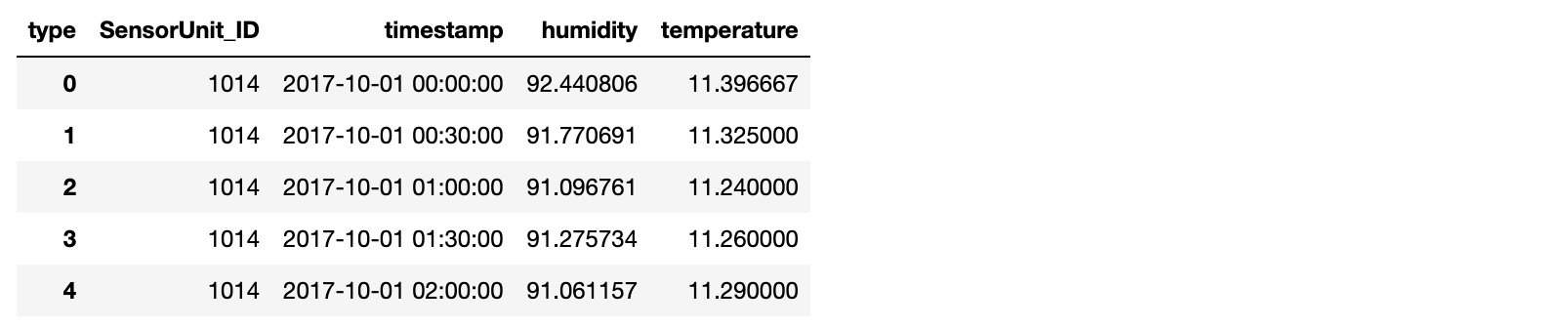
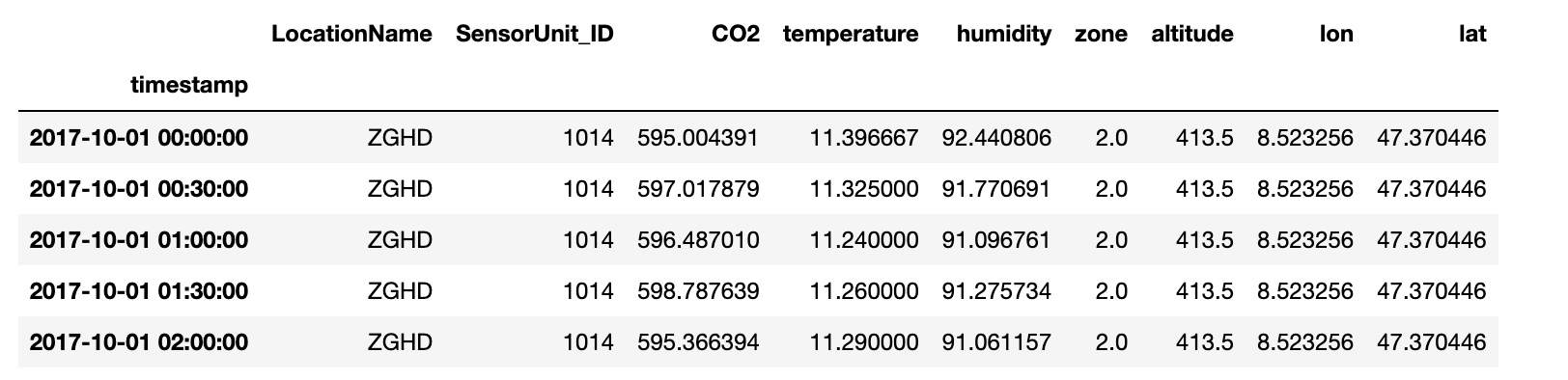
Merge the CO2_sensor_measurements.csv, temperature_humidity.csv, and sensors_metadata_updated.csv, into a single dataframe.
The merged dataframe contains:
index: the time instance timestamp of the measurements
columns: the location of the site LocationName, the sensor ID SensorUnit_ID, the CO2 measurement CO2, the temperature, the humidity, the zone, the altitude, the longitude lon and the latitude lat.
timestamp
LocationName
SensorUnit_ID
CO2
temperature
humidity
zone
altitude
lon
lat
…
…
…
…
…
…
…
…
…
…
For each measurement (CO2, humidity, temperature), take the average over an interval of 30 min.
If there are missing measurements, interpolate them linearly from measurements that are close by in time.