惨痛经验
Start easy
第一步,加锁,把Transactional Memory的功能写对。
- 测试报错Transactional library takes too long to process the transactions,是功能就不对,和线程数量、transaction数量、print没什么关系。
- 要把这个报错的阈值调大,修改grading里的slow_factor即可。刚开始可以直接改到1024。
先不要写什么优化,把基础功能写对,否则debug直接de到吐血
细节
- read_word()和write_write()虽然是照着project desciption写,但还是很容易出错,要很很很小心!
- free的时机需要注意,有时候free后再读并不是一眼就能看出来,bug藏得比较隐蔽。
Debug Segmentation fault
Segmentation fault常用debug操作:core dump(虚拟机环境不同,流程可能不一样,这里用了和DA project一样的ubuntu,最大的坑是找不到core)
设置
1
2ulimit -c unlimited
ulimit -arun
找到core文件
设权限
1
2cd /var/lib/apport/
sudo chmod 777 coredump/core移动到grading文件夹
debug
1
gdb grading core
gdb中常用
1
where
除了以上悲伤的故事,也有一些可喜可贺的习惯,给debug带了了巨大帮助,要继续保持:
- 每一部分debug输出用参数控制,可以很方便的开关。
- 经常commit。避免debug变成写bug时,回退都无处可退。
备注:下文所有TM指的是Transactional Memory,不是口吐芬芳。
阶段一
写完read、write等基础操作,先加了个全局锁,放到虚拟机里测一下逻辑。
atomic_load时segmentation fault
本地跑没问题,但是虚拟机里make build-libs run就Segmentation fault。一番折腾后,定位到是atomic interger的问题。用atomic_store或者atomic_load的时候就会报错。
尝试1
在计算control structure的偏移量时,第一个segment没转(void*),于是取地址出了问题,atomic_load时就崩了
1 | (void*)segment+segment->offset_control+CONTROL_SIZE*index |
改成这样本地跑又取不到了,就离谱
尝试2(结构体指针)
怀疑是结构体指针的问题,打印了一下相关的值
1 | struct segment* segment; |
前三个是一样的,符合预期。那么计算偏移量的时候是否也一样?
1 | DEBUG offset=208 |
这里算出来就不一样了
b530-5a30 = 0x5b00 = 23296 = 208 * 112
而112正好是struct segment的大小,所以不转换直接加,单位是struct size
5b00-5a30 = 0xd0 = 208
这样就是对的,所以应该先转换指针类型
那么尝试1加了(void*)应该方向是对的
control修改错误
接上一个bug,改完之后,发现set control owner出现问题,没有set成功
1 | [owner=0 v=0 w=0 s=0] |
写内存成功了,在函数内部打印control也是对的,但是结束之后整体print region时,control是空的
解决:
打印发现两次用control时地址不一样。是后面算control起始地址没有改过来,仍是直接算的,没有用定义的宏
改过来之后顺便检查了一遍,所有计算control地址的位置,都是用宏
batch间reset control后segmentation fault
目前本地测试一轮中的transaction没什么问题,但是tm_end()、调用batcher_cleanup()之后,打印region出错
1 | --------segment1-------- |
应该是segment2,而不是0
尝试1
在batch_cleanup()中打印了一下segment id
1 | while(segment){ |
发现第二次是0
可能是segment指针的问题
但是print_region()里面也有这个循环,没有问题,那边是这样写的
1 | while(segment != NULL){ |
总不能是!=NULL的问题吧
试了一下,果然不是
尝试2
在batcher_cleanup()的循环里加了强制类型转换,好了一次,再测又不行了
1 | segment = (struct segment*)(segment->next); |
尝试3(内存分配)
打印region和segment的地址都是对的,但是为什么读出来东西就不对呢?
仔细看了下两块segment的地址
1 | --------segment1-------- addr=0x7f9bc9c05a30 |
a30和b30这才隔了256,肯定会撞吧!难道是一开始分配就有问题?
初始化时的代码是
1 | struct segment* segment; |
看了下reference代码,先malloc的region,后面才posix_memalign的segment
改成
1 | size_t total_size = sizeof(struct segment) + size*3 + size/align*sizeof(atomic_uint_least64_t); |
成功!
现在的地址是
1
2
3
4
5
6
7
8
9
10--------segment1-------- addr=0x7fde98405b20
[0] 00000000 | 11111111 [owner=0 v=1 w=0 s=0]
[1] 00000000 | 11111111 [owner=0 v=1 w=0 s=0]
[2] 00000000 | 22222222 [owner=0 v=1 w=0 s=0]
[3] 00000000 | 22222222 [owner=0 v=1 w=0 s=0]
--------segment2-------- addr=0x7fde98405d10
[0] 00000000 | 00000000 [owner=0 v=0 w=0 s=0]
[1] 00000000 | 00000000 [owner=0 v=0 w=0 s=0]
[2] 00000000 | 00000000 [owner=0 v=0 w=0 s=0]
[3] 00000000 | 00000000 [owner=0 v=0 w=0 s=0]
d10-b20 = 0x1f0 = 496
阶段一测试
丢进虚拟机跑grading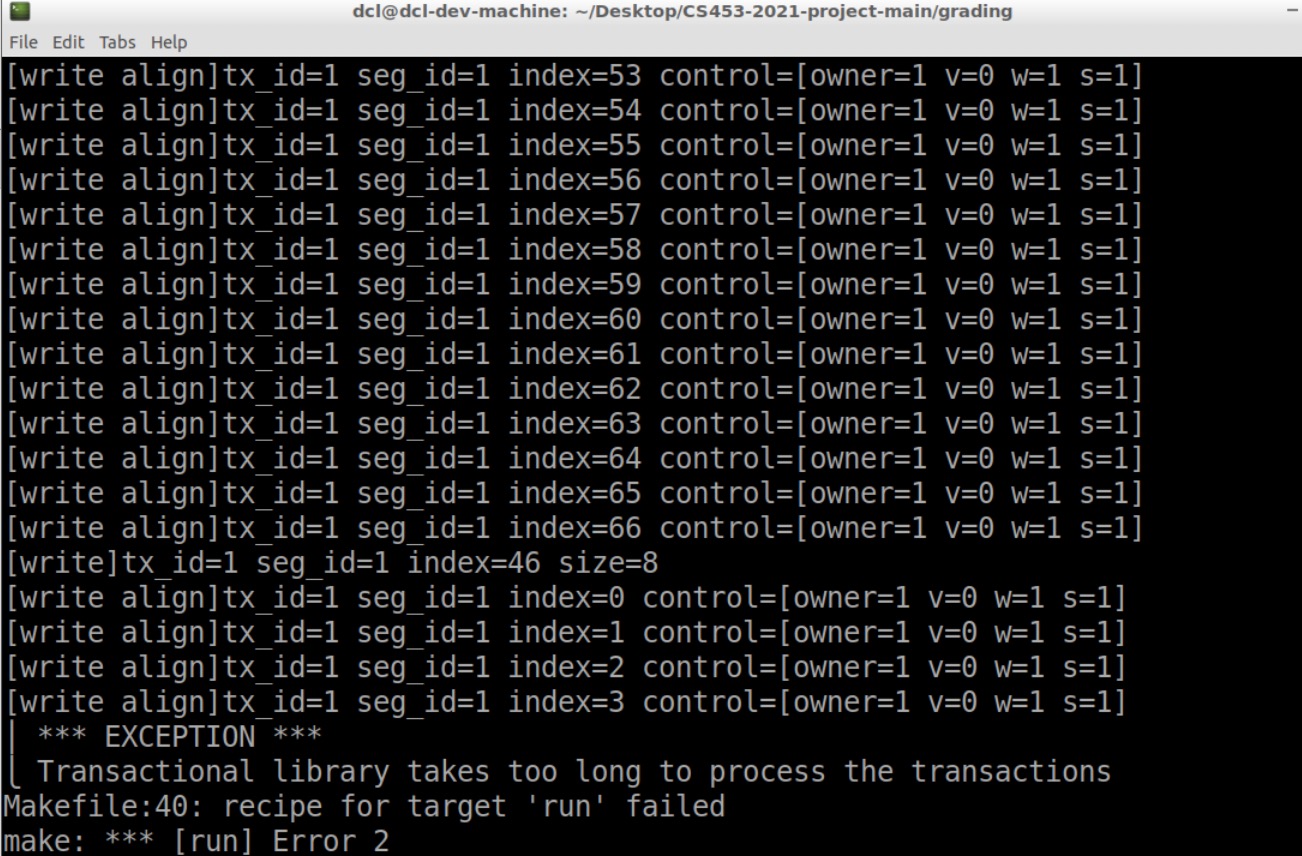
用时太久,正常。但是没有segmentation fault了,应该read write操作也没什么问题了,第一步完成!耶!
停掉了一些print,减少不必要的时间浪费,测TM相关函数
malloc错误
1 | [batcher_cleanup] region addr=0x7f1bc8000b20 |
像是个和内存分配有关的bug
Why do I get a C malloc assertion failure?
检查clean_up_segment里的循环
1 | for(size_t i=0; i<segment->size; i++) |
终止条件写成了segment->size,应该是size/align
解决!
时间太长
现在grading输出是
1 | [write]tx_id=1 seg_id=1 index=63 size=8 |
可能是用时太长,也可能是read有问题,先检查后者
单独打了一下read的输出
1 | [read align]tx_id=2 seg_id=1 index=64 |
可以跑,那应该就是用时太长的问题,而不是逻辑问题
那么接下来就可以开始改并发相关的代码了
虚假的阶段二
前面基本测试了TM的read、write、alloc功能,现在把全局锁换成batcher
时间太长
现在的问题是
1 | ⎪ *** EXCEPTION *** |
尝试1
把参数调小了还是很慢
看了下具体输出
1 | transaction created. id=32 addr=0x7f35dc00d3d0 log_size=100 |
似乎batcher的enter有问题,blocking length不对
…
一开始初始化把1写成0了
1 | static unsigned int const_zero = 0; |
尝试2(逻辑错误)
改batcher、换回锁,总是第一个transaction可以跑到batcher cleanup,第二批就不行,也许是中间清理有问题
但是本地测试并打印region,应该没问题
在虚拟机里加入了具体的R/W输出,发现第二轮的read卡住了
继续查发现read没问题,但是read之后write就写不进去了
发现是逻辑问题:写的时候,如果还没写过,会尝试gain_owner,但是如果自己已经读过了,需要判断owner是自己
但是虚拟机里跑还是不对,第一次read align返回了,但是没有后续了
发现是tm_read()最后应该return flag,写成了return false🤪
现在报错变成
1 | ⎩ Violated isolation or atomicity |
终于可以进行下一步了
阶段一’
Violated isolation or atomicity
现在还是直接加锁,atomicity有问题只能是逻辑问题,一夜回到阶段一,又得开始找read、write、alloc的bug
多次测试,报错有2种,一个是violate atomicity,另一个是
1 | [tm_begin 2] |
尝试1
怀疑是segment的问题,因为本地没怎么测alloc、free
但是加了输出,发现并没有调过这两个函数
尝试2
奇怪了,看输出没什么问题,到底是哪卡住了?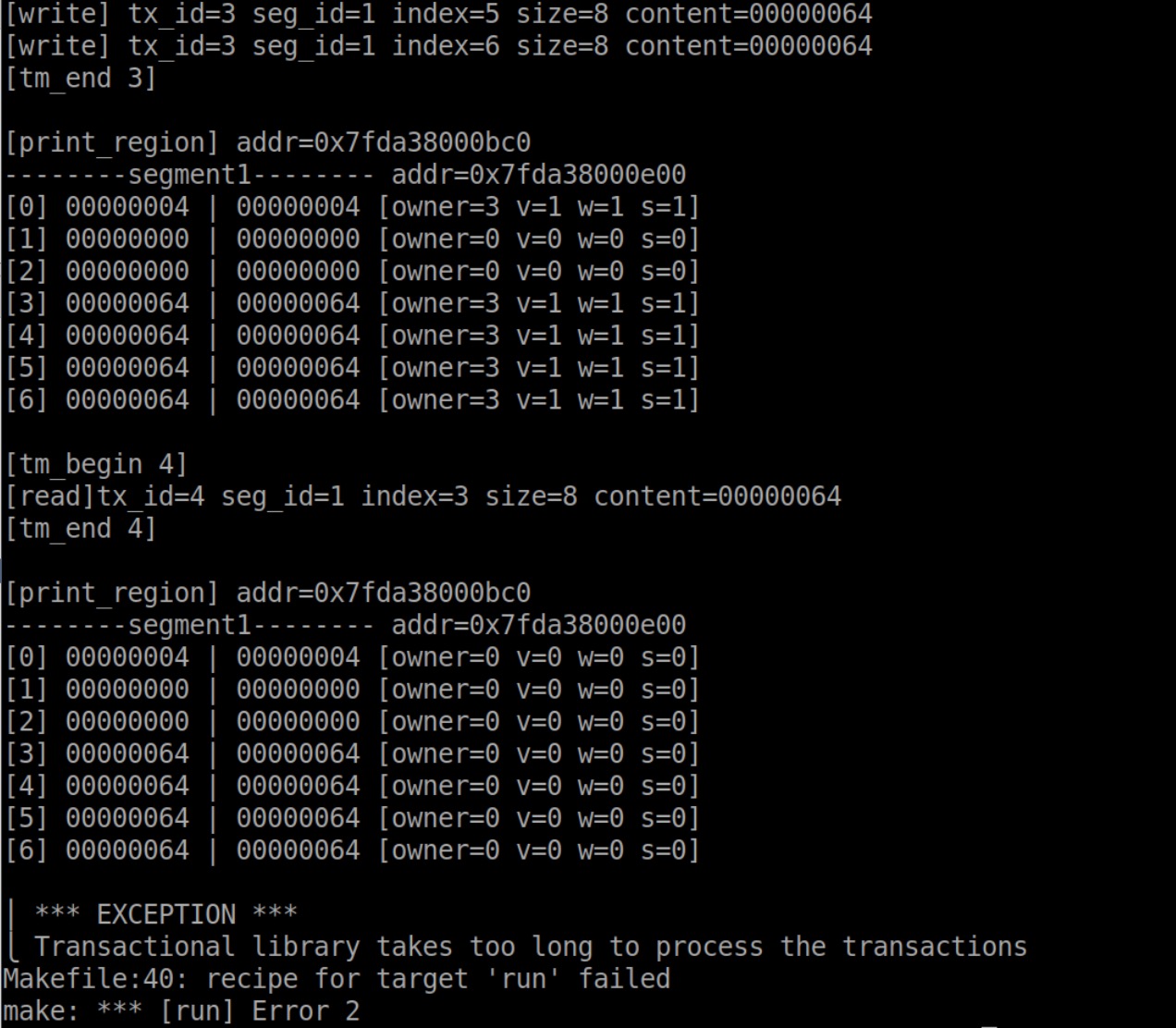
另一种情况是,可以继续跑,跑到最后violate atomicity
定位到一个bug!先read再write没有写write_flag!
但是对这里影响不大
尝试3(逻辑错误)
定位到yigebug!先write再read,读的是旧值!这个问题比较严重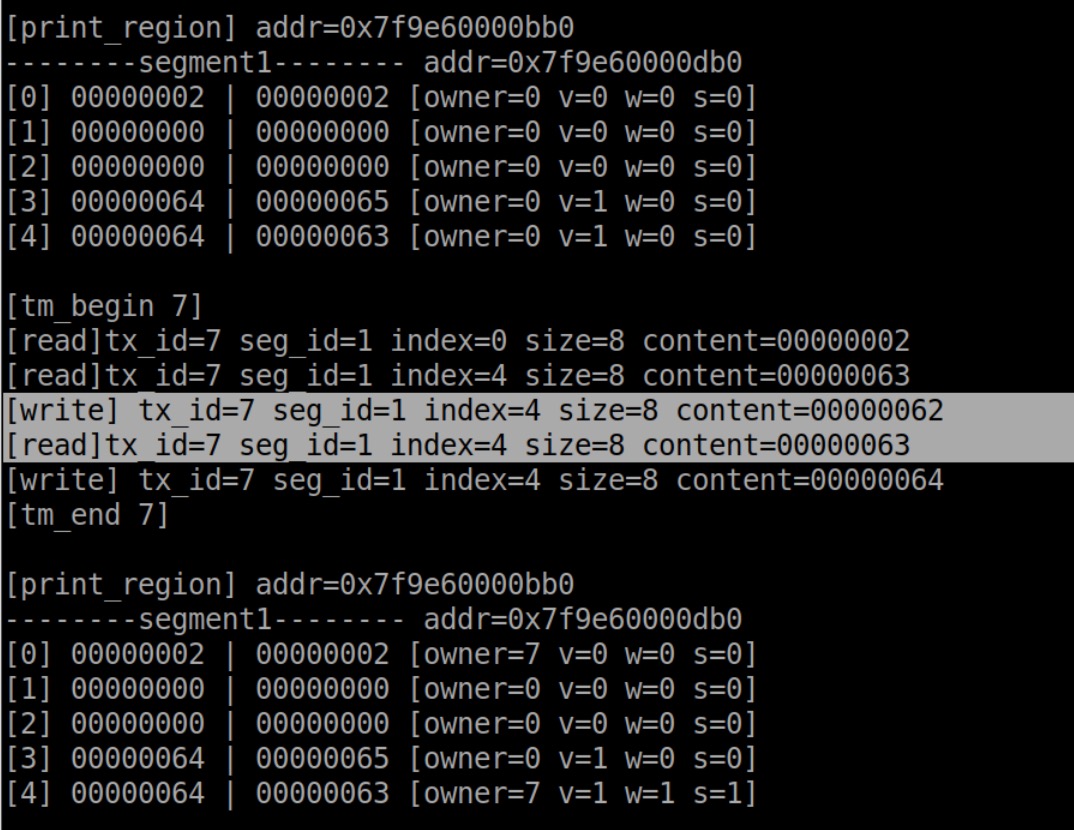
现在的代码:
1 | // read the writable copy into target |
这明显调的函数都和注释写的意思不一样啊🤪
时间太长
现在的报错都是时间太长,会不会是其它线程被堵太久了?
把线程减到1个,大部分还是时间太长,有一个跑完了!感动!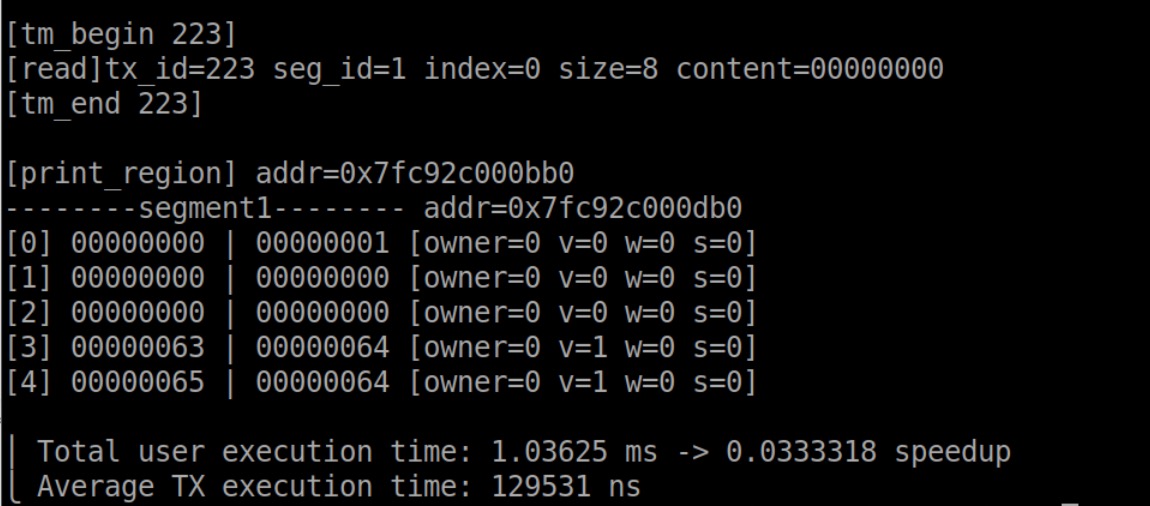
把Slow trigger factor从8调到1024,都跑完了!感动!
也就是说,单线程的时候,read write没问题了!(测试里好像没有alloc free?)
改到2个线程,也可以跑!呜呜呜呜呜
一波未平一波又起,此时虚拟机出现了bug
罢了,做饭去
下午。
把grading的参数全部调回默认,除了slow_factor设成1024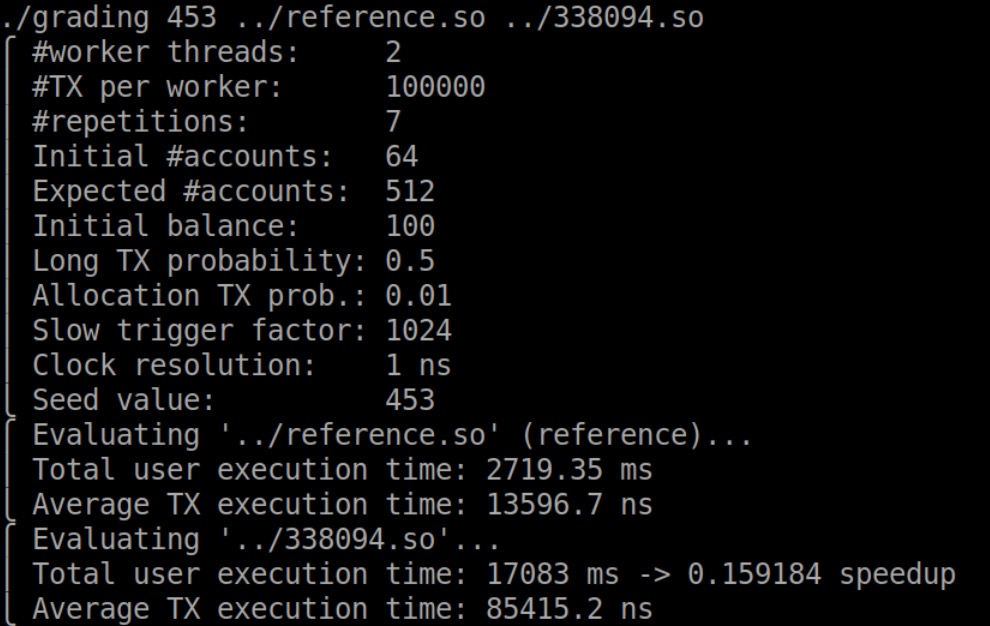
对了对了!可以开始写batcher了!
阶段二
开始测batcher,这次要一步、一步、一步来
Too long
开四个线程时,有时会卡住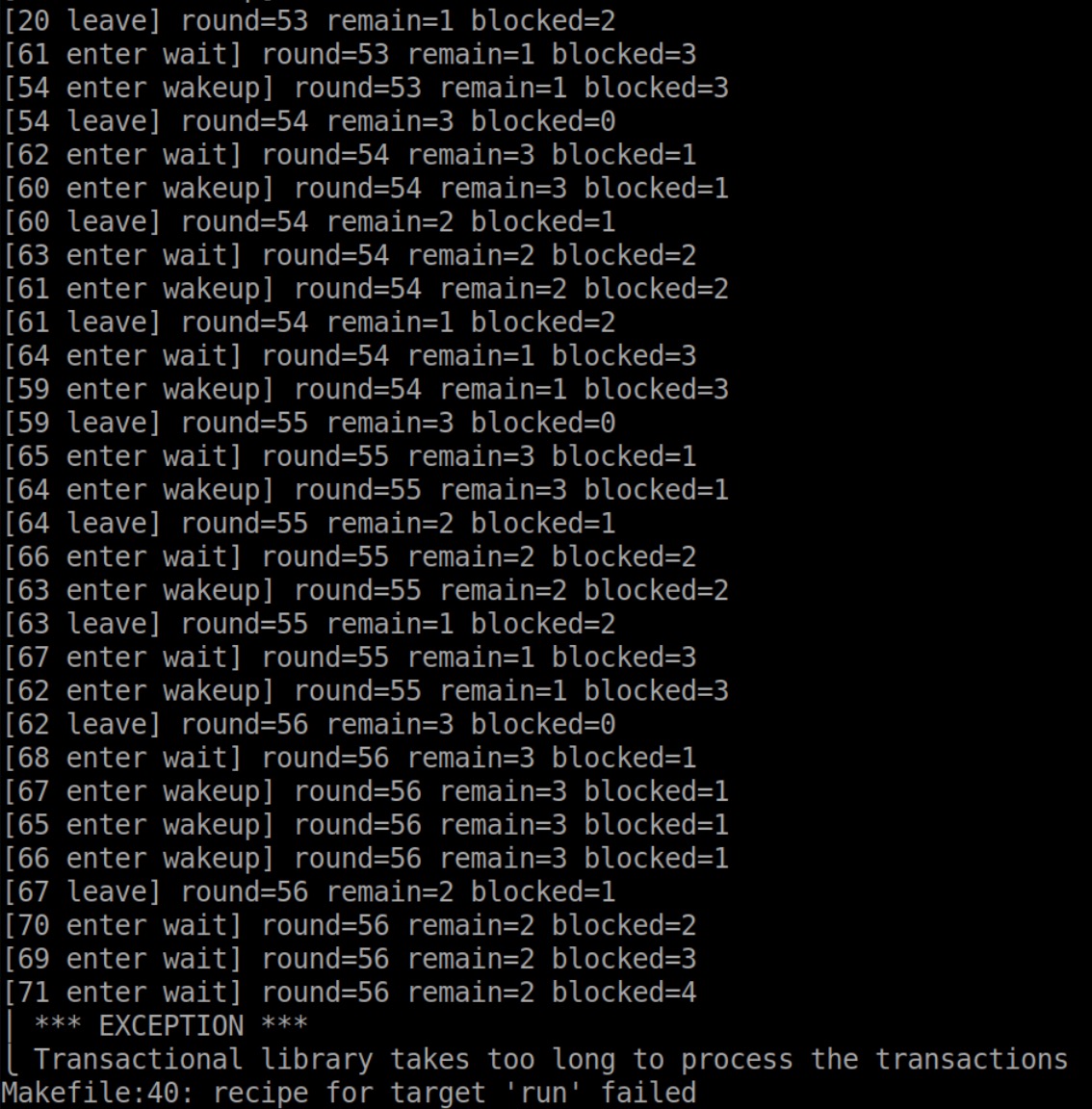
感觉是某个transaction时间太长导致的
发现问题!如果有操作abort了,用户不会调tm_end
在read write失败时调leave(),解决
没有core文件
想用coredump debug,运行显示
1 | make: *** [run] Segmentation fault (core dumped) |
但是没有core文件
最后在↓的最后一个回答找到解决
Where do I find the core dump in ubuntu 16.04LTS?
found the core dunp in /var/lib/apport/coredump/
core在不同文件夹,想移到同一个文件夹比较方便,拖的时候permission denied,先改了下权限
1 | sudo chmod 777 coredump/ |
然后就可以debug了
1 | gdb grading core |
发现是leave()的问题
1 | #0 0x00007f13e809812c in leave () |
但是没有显示行号,在编译时加-g(改Makefile)也不行
Violated isolation or atomicity
添加了read log、write log、transaction log,加锁测试通过,改成batcher后报错
发现1或2个线程时,结果正确,4个线程会出错
发现竟然是因为开着DEBUG_READ和DEBUG_WRITE,可能是写debug output时同时访问,但是没有做同步控制,导致出错。关掉输出就好了
Violated consistency
现在大部分时间没问题,有时会出这个错
重新读了一下consistency的定义。难道是如果process读了一个值,后面这个值被改了,也得abort?但是如果被读过,这个值后面应该不能修改了。
尝试1
也许是因为read align和write align中,有时有多个判断,这些判断单独都是atomic的,但是合在一起就不是了。
改了一些逻辑,合并判断和交换,还是不对。
尝试2
在workload.hpp里加了一堆输出,打印具体是哪里出错,发现一个常见问题是check()中counter!=0
可是这个counter是什么鬼?
1 | Shared<size_t> counter{tx, tm.get_start()}; |
找到定义
1
2
3
4
5
6
7
8public:
Shared<size_t> count; // Number of allocated accounts in this segment
/** Binding constructor.
* @param tx Associated pending transaction
* @param address Block base address
**/
AccountSegment(Transaction& tx, void* address): count{tx, address}, next{tx, count.after()}, parity{tx, next.after()}, accounts{tx, parity.after()} {}
好像和transaction数量有关,会不会是最后没有free?
并不是。
1或2个线程的时候没事,3个以上出错,难道是OTHER的问题?
又检查了一遍逻辑感觉也没什么毛病
尝试3
现有的2个报错分别是
1 | ------WL5------ counter=16 |
和
1 | ------WL1------ sum=61 |
后者似乎导致了前者,需要先解决。
一个现象是,每次差的值都是1,而不会更大
加到8个线程会出现:
1 | ------WL1------ sum=637 |
总之基本偏差不大,像是哪里有个细节不对,但是到底在哪啊💥
但是counter最后的的偏差又很大…
把transaction数量减小之后,只发现Violated consistency,而没有Violated isolation or atomicity,不会是哪里溢出了吧?
就10和100的区别,也不至于啊。
尝试4
又开始读workload.hpp,这个count应该就是所有segment里面account值的和,加起来应该等于预期。那么这个值错了,其实还是read、write的问题。
给read、write加锁,还是同样的报错。那么难道是batcher的问题?
又多打了一点输出,上面Violated isolation or atomicity这个问题都是出现在 Long read-only transaction, summing the balance of each account中,其实也就是在检查实际进行操作的short transaction的结果是否正确。
再想想,参数小的时候,出错误一,参数大的时候,出一和二,那么还是应该一是更根本的。而一的关键在于counter,最后应该为0。那么这个counter到底是个什么啊???
尝试5(CAS条件)
仔细读输出,找到了一个bug!!!一下午了,终于见到实际的bug在哪了!!!第一次见到bug这么激动。
有write之后,竟然又读成功,还改了owner,简直离谱。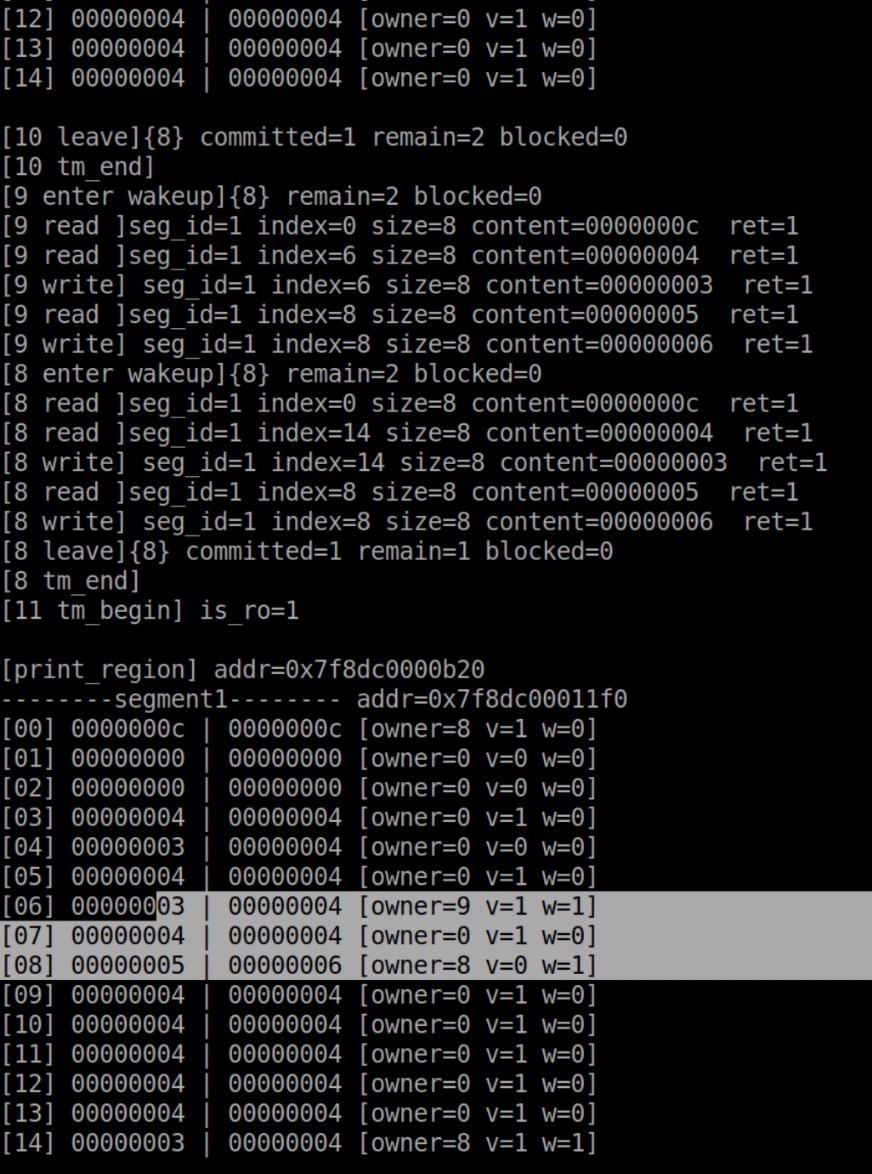
多加了一些输出,轻松复现这个bug。都是有2个transaction,A读写位置1、位置2,B在A之后读写位置3、位置2。正确情况应该是B读写位置2失败,但是现在 成功了。
问题在于read_align()
1 | // if the word has not been written in the current epoch then |
比较的expected值不应该是load到的值!而是判断如果owner是自己,应该是的值。
Reset错误
改完这个又发现一个bug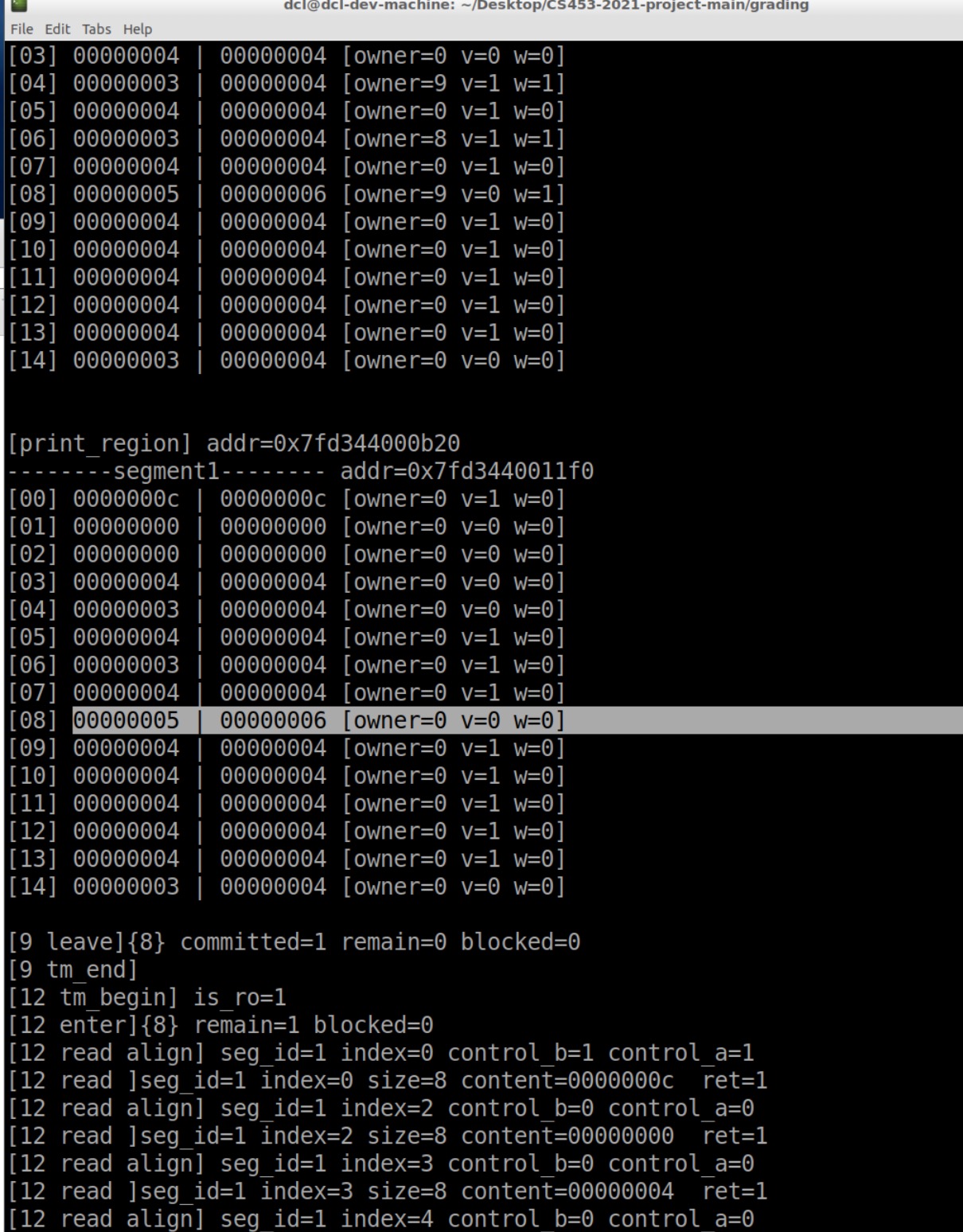
A写了位置9,之后B也想写位置9但没写成功,最后没有交换valid。
也就是说,B先退出,调用clean flag,此时由于B没有成功,直接将control清空了,9写的WRITE_FLAG也没有了。
加一个判断,只有自己是owner时才reset,应该可以解决问题。
现在没有Violated isolation or atomicity的问题了(或者没碰到)。
暂时测试可以正常跑完了。
阶段三
batcher的功能写对了(但愿),接下来尝试在服务器上跑通(20 threads和10000 transaction per worker)。
Floating point exception
为了避免每次clean segments遍历整个内存,将修改过的地方记了log,但是上服务器log会爆掉。
改成了overflow的时候realloc四倍空间
然后就出现了
1 | make: *** [run] Floating point exception (core dumped) |
尝试1
gdb grading core一下
1 | [New LWP 2519] |
…说了个寂寞
尝试2(free之后)
发现是上次设置的core dump参数在虚拟机重启后没有了,需要重新再来一遍。
1 | ulimit -c unlimited |
权限也要重设。
然后就可以看core dump文件了。
1 | Program terminated with signal SIGFPE, Arithmetic exception. |
竟然是read里面浮点异常?read里面浮点都没有啊哪来的异常???
1 | Core was generated by `./grading 453 ../reference.so ../338094.so'. |
这次在clean_log()里,还靠谱点。
1 | [clean_log] size=8 |
好家伙!真是除0啊!
打印发现segment id是0,明显是访问到了不该访问的segment,要么是起始地址算错了,要么是遍历错了。
会不会是clean了已经被free的segment啊?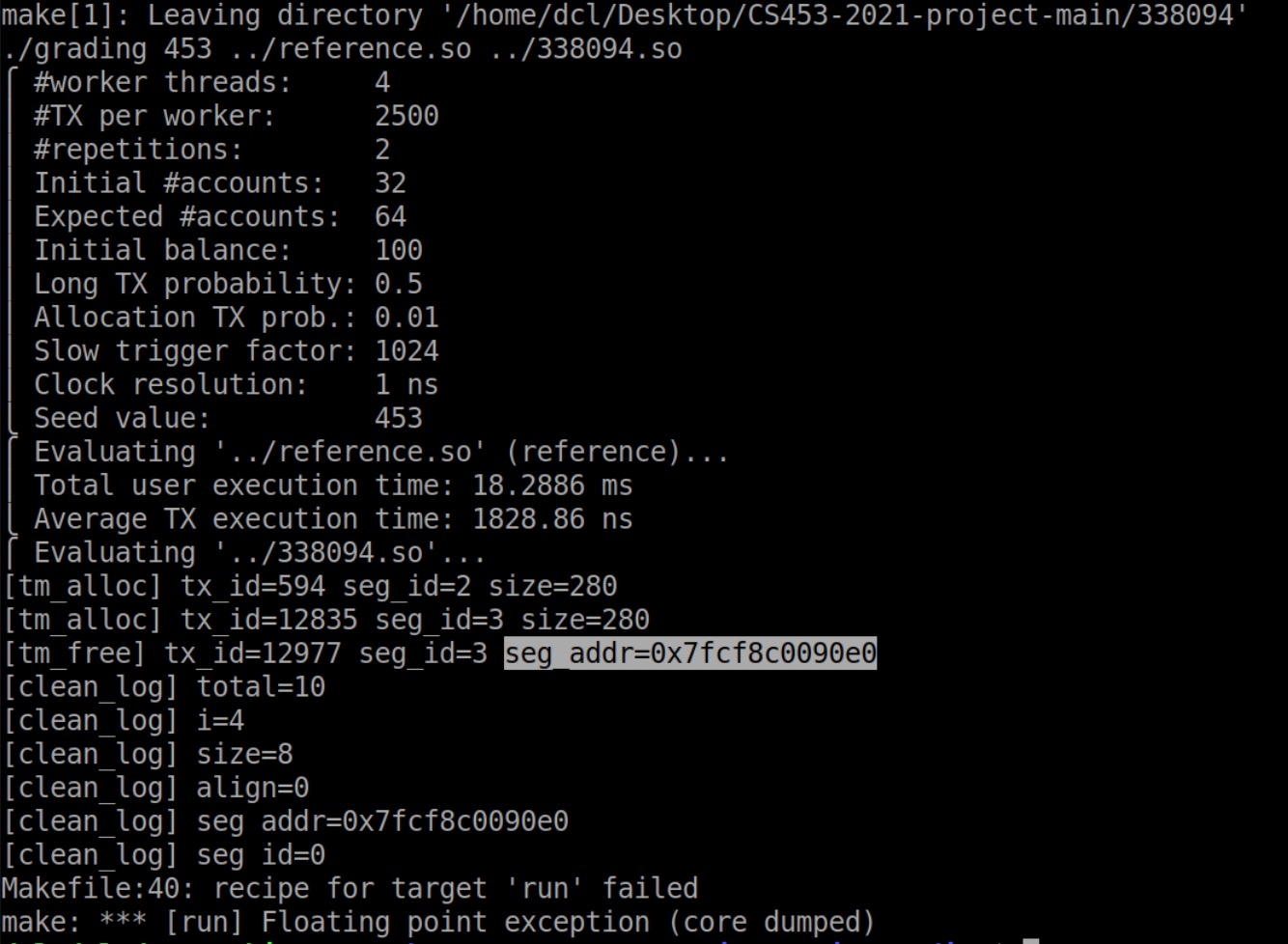
果然!
所以是因为,read、write的时候写了log,一轮结束的时候根据log里的地址去重设control。但是可能其中有的segment已经被free掉了。
改成defer到tm_destroy再free segment,成功!
Segmentation fault
上服务器跑一下:
1 | [ERROR] write log overflow!⎪ *** EXCEPTION *** |
log写死512不够。
试图在虚拟机里复现bug,参数调到
1 | auto const nbworkers = 4; |
时,又出现了Segmentation fault,查看core
1 | Program terminated with signal SIGSEGV, Segmentation fault. |
是log的问题
奇怪的是,打开clean的debug输出后,报错变成
1 | [batcher_cleanup] total=2 |
先把slow factor调成1024
发现有时候read log满了
1 | [78516 clean #write=0 #read=512] |
1 | batch round -> 56620 |
不是设置过read only不写log吗?发现代码里没有,可能是前面哪次debug回退删掉了🤪
重新加入判断:is_ro时不写log、不清理,成功!
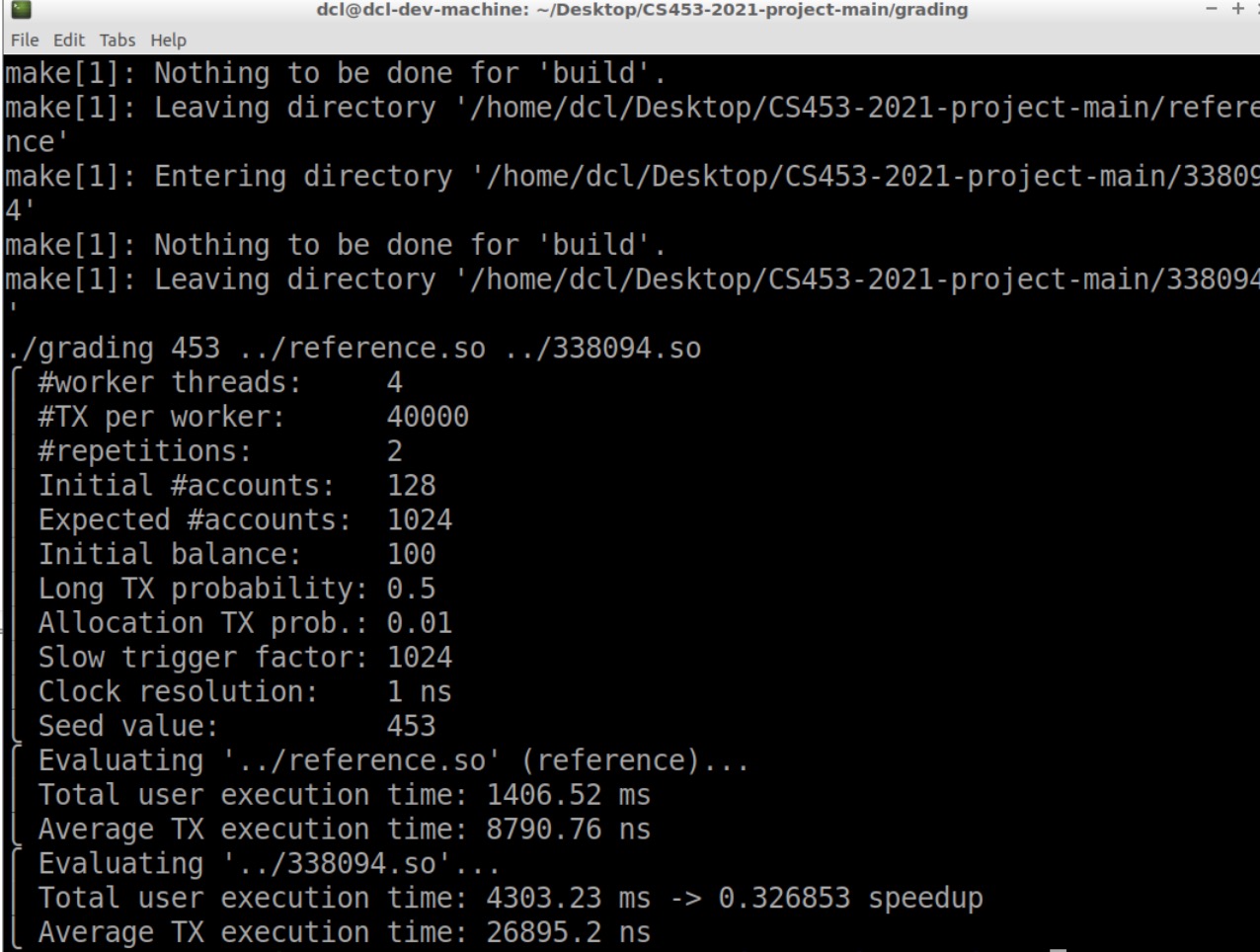
现在跑↑这个参数可以过了!可喜可贺!
log overflow
上服务器!
write log overflow😭
512,不够
1024,不够
2048,不够!
虚拟机调成相同的参数试试。至少有一个好消息,虚拟机的报错现在和服务器一样了!也就是说, 可以直接在虚拟机上测试一下log的大小。
可是虚拟机2048够了啊?见鬼。
等等…刚才上服务器改了参数忘记重新打包zip了…2048重新试一次
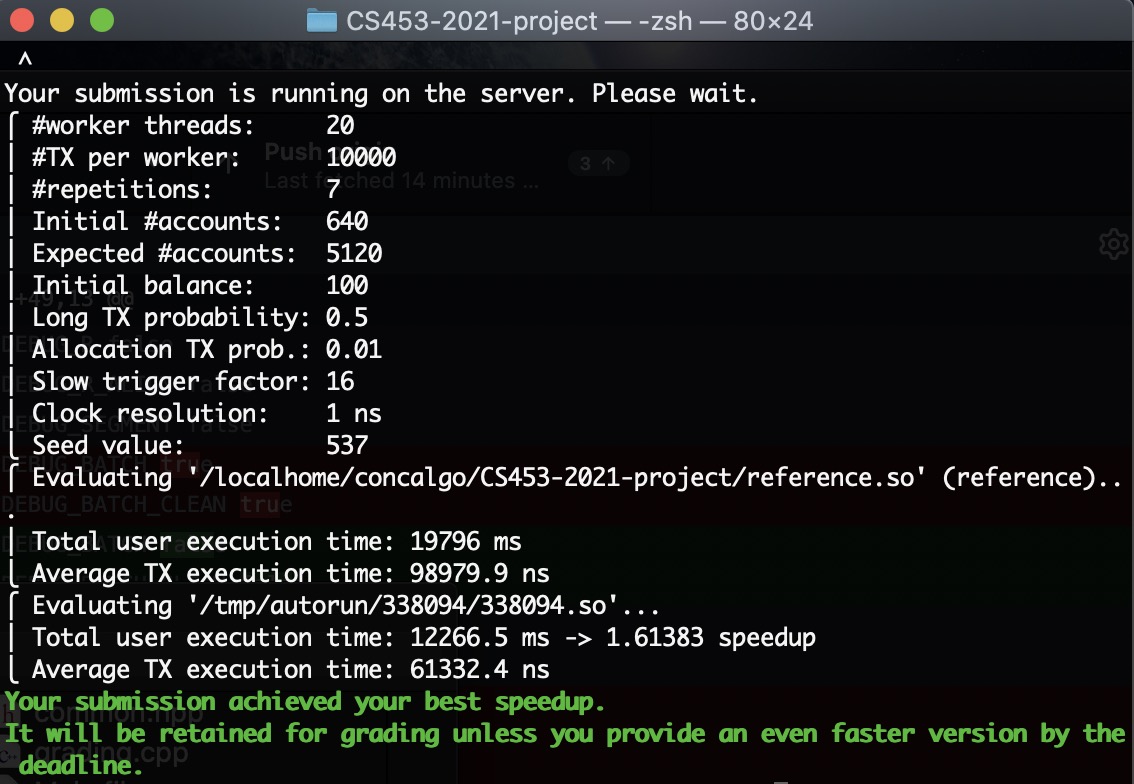
啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊!!!!!!!!!!!!!!!!
虚拟机1024也能过,要不上服务器再试一次。果不其然!过了!哈哈哈哈哈!
Milestone
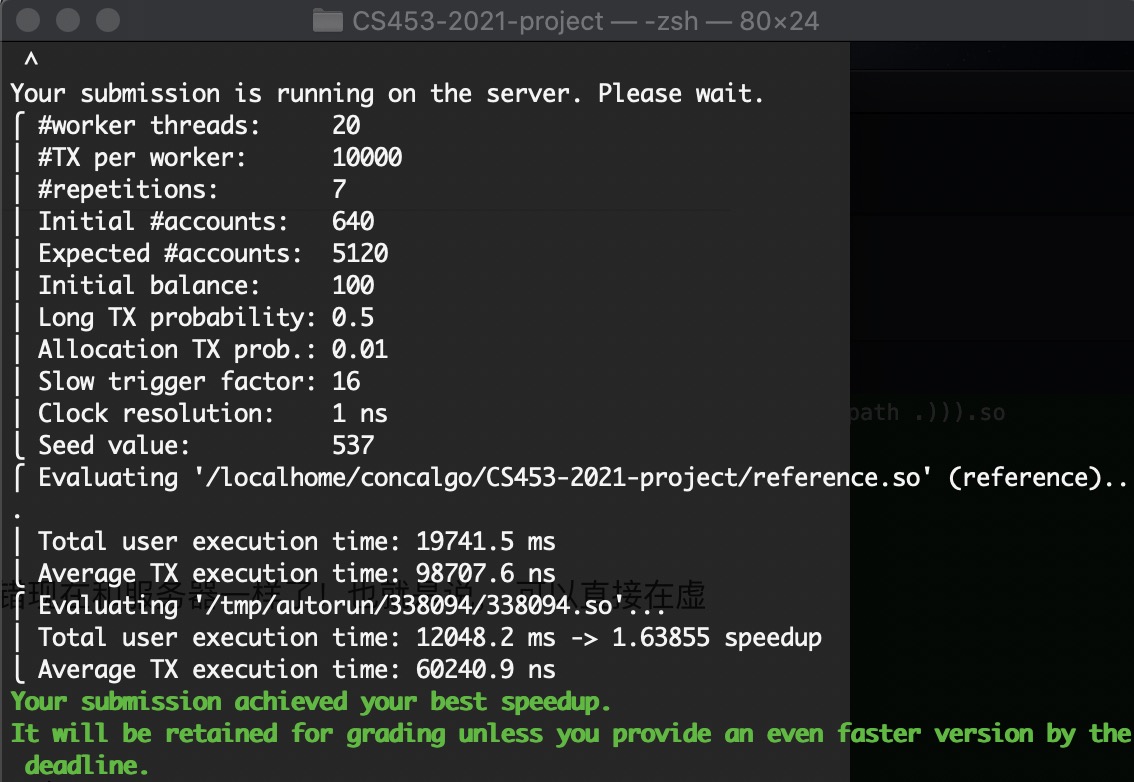
太感动了!
第一次过,绿色,竟然有1.6!活过来了!
从11/28开始写这个版本,断断续续写到今天12/13,差不多两周,终于,及格了😭😭😭
(虽然中间还写了个DA project submission3,DA可真是太友善了,我爱Java)
阶段四
尝试改进,提高性能。
BoundedOverrun
1 | terminate called after throwing an instance of 'Exception::BoundedOverrun' |
发现是优化逻辑后read_only transaction没有free
Memcheck
下面主要是用Valgrind检查内存泄漏时的问题。
解决上面的问题后还有泄露:
1 | ==2068== 32 bytes in 1 blocks are still reachable in loss record 1 of 2 |
应该是read only在read失败时,不会调用tm_end,所以应该就地free。
果然。迅速解决!耶!