Project0要求实现Perfect Link,给了测试用的tc.py用来修改网络情况,stress.py模拟发消息。(Distributed Algorithms 2021-2022 Project Validation.pdf)
想测一下试试。
注:以下几个测试都没有改tc.py的参数,即↓
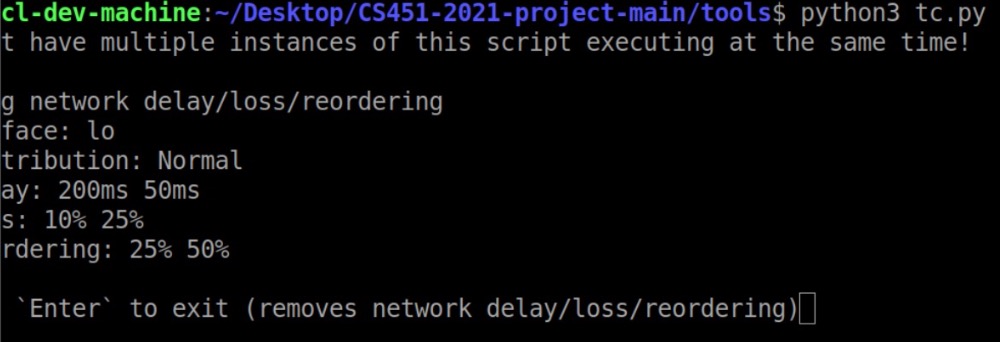
Round 1
参数如图:
1 | testConfig = { |
1 | python3 stress.py -r ../template_java/run.sh -t perfect -l output -p 10 -m 10 |
testConfig在stress.py最后,这里全是默认,10个process,每个发10条消息(config中只有一行 10 1)
理论上来说,应该是2-9号都要给1号发10条,总共90条
但是出来的数据不完全是90
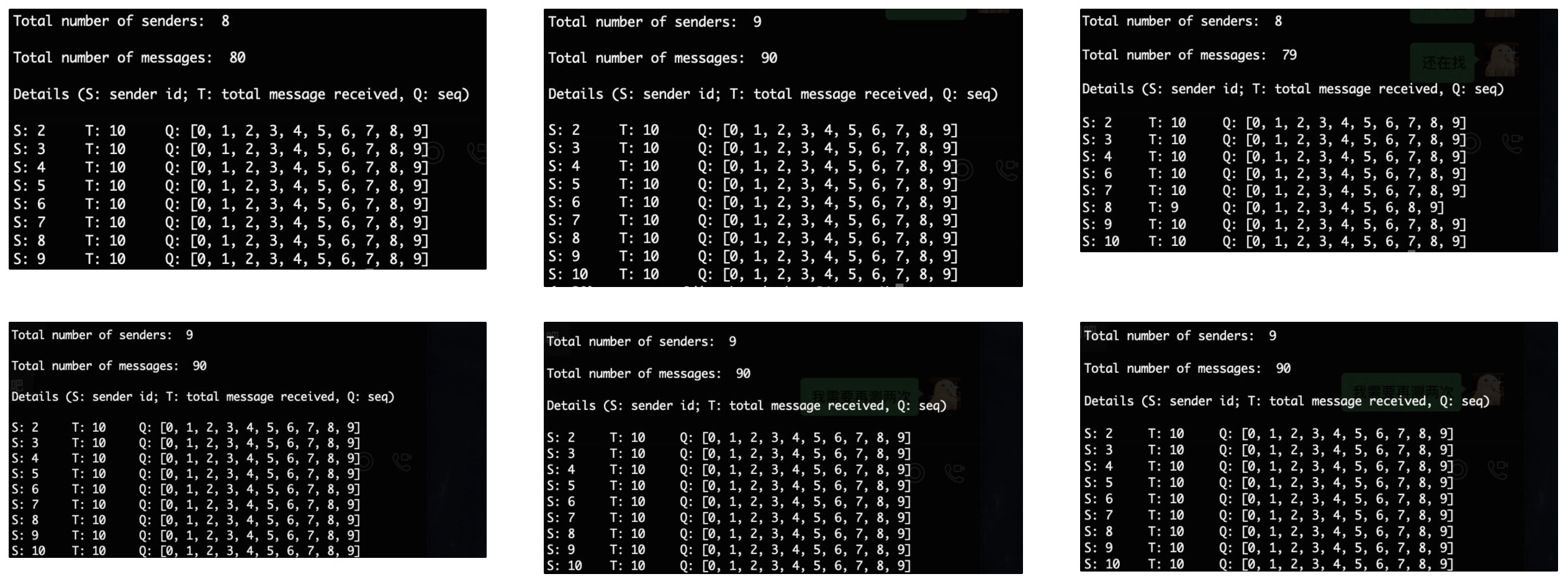
(这里统计输出写了个简单工具,见最后)
根据后面测试的结果推测,问题在testConfig这里。concurrency和attempts数值都是8,也就是有8个捣乱线程各干预8次。STOP和CONT只是暂停和继续,不会干扰最后的结果。但是这里还有0.04的概率会发TERM,直接把正在干活的process杀了。所以最后有的只发了79、80
Round 2
1 | 'concurrency' : 16 |
试了几次这个参数,情况差不多。应该有19*20=380条,但是结果分别是:267、299、360、319
突然
经另一位当值的昆虫馆管理员提醒,测试进程数是有上限的

对不起我的CPU🙇♂️
(但是这里到底是在说9 100是上限,还是举个例子说如果9 100,让跑25分钟???)
Round 3
于是就把p和m直接设成9和100
意识到TERM可能会对correctness有影响,这里把TERM也调成了0
1 | 'concurrency' : 8 |
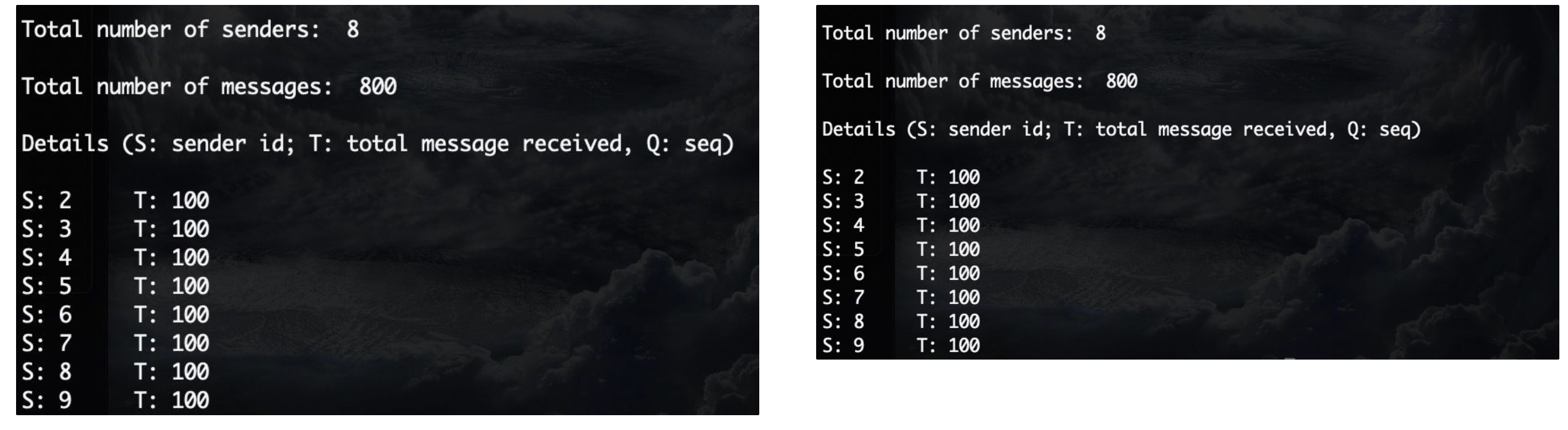
输出没毛病
Round 4
然后把TERM改回去
1 | 'concurrency' : 8 |
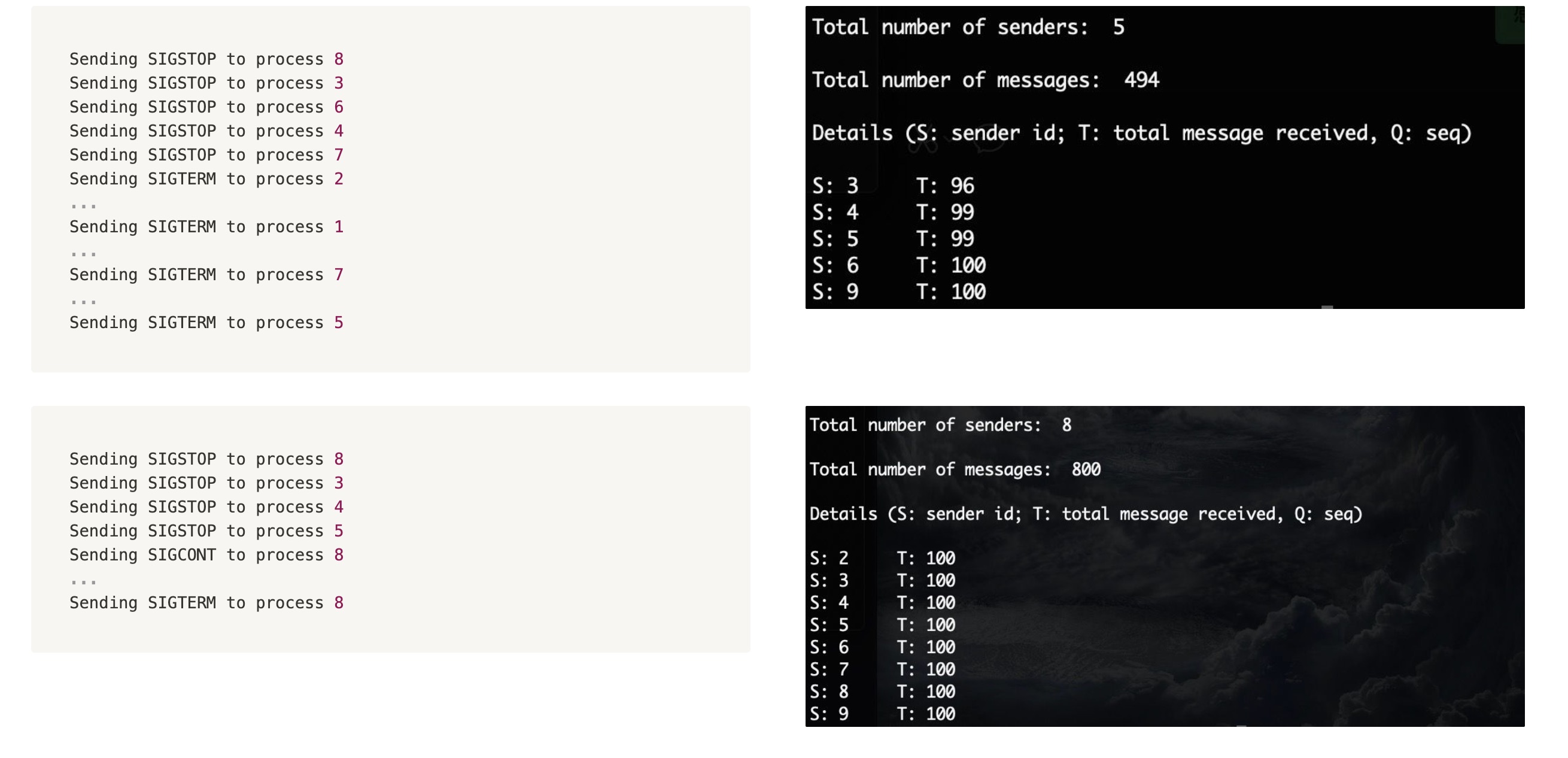
左边是运行中部分输出
可以发现有的process被SIGTERM杀掉了,第一次SIGTERM多一些,最后收到的少一些。第二次最后才有一个SIGTERM,此时已经发完了
符合预期
Tool
由于输出长得实在没眼看,不好debug,写了个工具统计一下
这两放一个目录下:
- count.py
- output.txt
output.txt是stress.py的输出(只是process 1的output,全是deliver没有broadcast的,长这样↓)
1 | d 2 81 |
count.py
1 | with open("output.txt","r") as f: |
后面输出多了,可以把具体的SEQ删掉掉,前面少的时候可以看看有没有重复