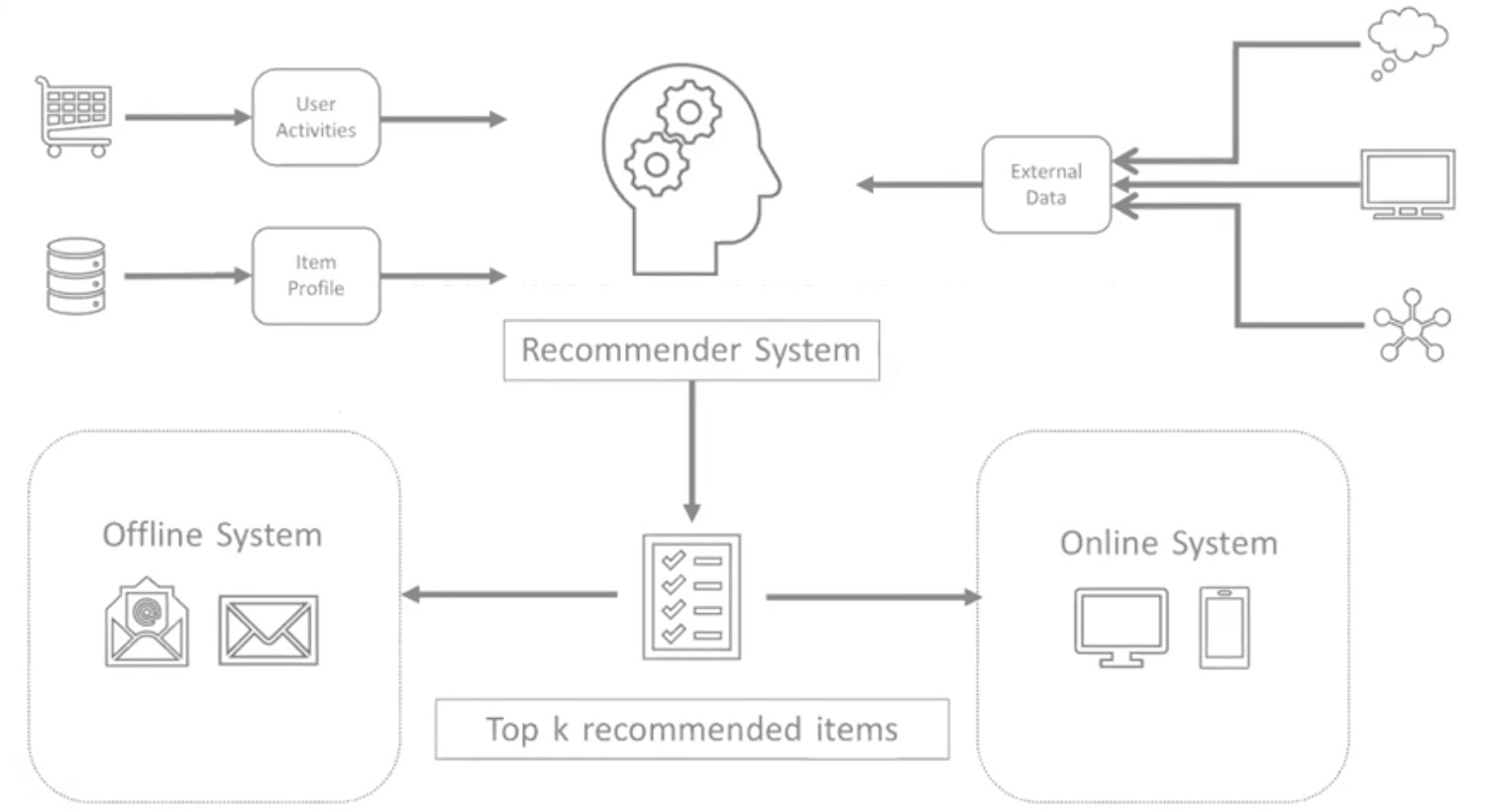
Overview
传统推荐系统
Content-based:unstructured,文字、图像等,需理解语义、提取大量特征,算法复杂延迟高
Collaborative filtering协同过滤:基于User、Item历史,如点击是1、不点击是0
Demographic:地域信息
Knowledge-based:根据专业知识
Community-based:类似Content-based,如社交网络、人群兴趣
Hybrid:综合
协同过滤
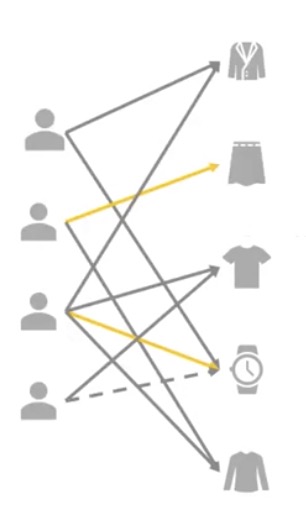
基于相似User判断
计算相似性
- Memery-based
- Item-based 如,把Item转成矩阵计算相似性
- User-based
- Model-based 建立User和Item的方程,给定一个User和Item返回一个分数

思想:根据User-Item Rating矩阵,学到User和Item低维的特征表示,用它计算相似性
购买为1,点击未购买为0,剩下补0
矩阵分解:降维 找一个矩阵代表User,一个代表Item,相乘得到
可做Regularization
优点
- Easy to implement,系统简单,响应快
- Content-independent,与用户其它特征无关,不需要获取这些信息即可实现
缺点
- 数据稀疏
- Cold-start problem 如新用户特征向量全0,无法计算
- Do not consider content
深度学习
优势:表征能力强、不需要做特征工程、
先创建深度学习的网络结构实现协同过滤,再加入Content-based
Neural Collaborative filtering
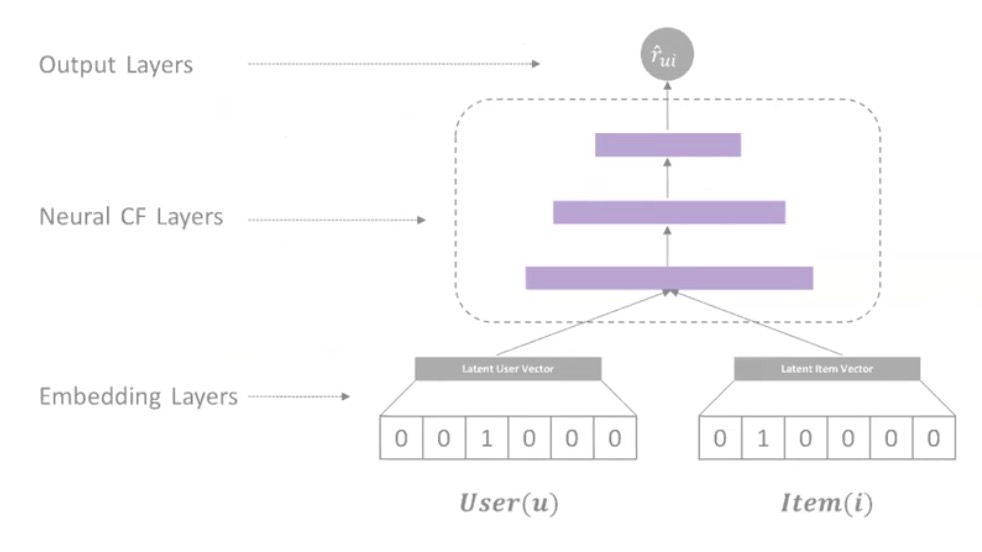
Embedding Layers
- 把任何一个User、Item变成一个低维向量
- One-Hot Encoding
Neural CF Layers
- 做矩阵分解
- 可以加隐藏层,学习非线性表征
Neural Matrix Factorization Model
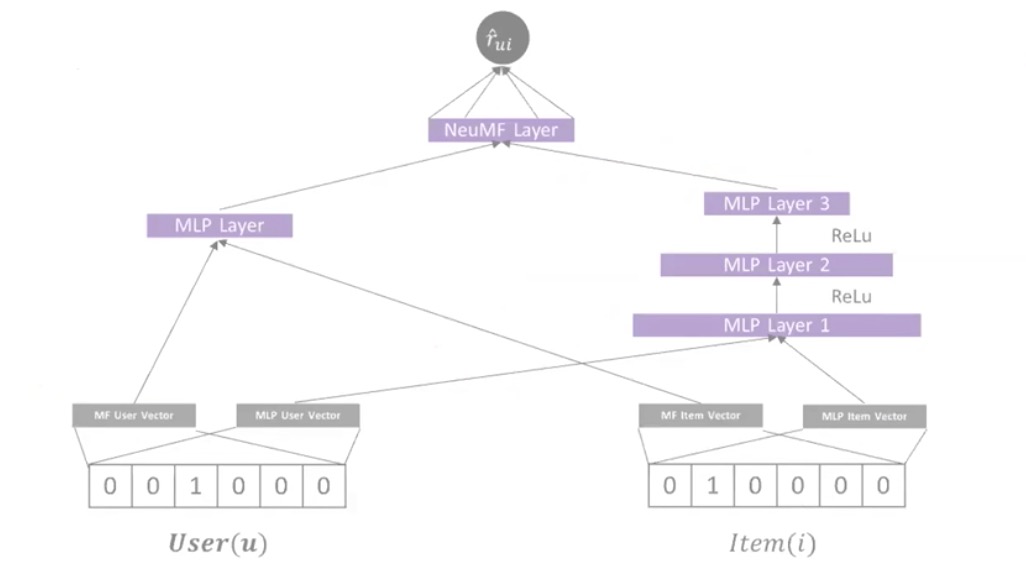
线性的和非线性的结合到一起
问题:没有Content-based,希望加入手工提取的特征
Wide Deep Neural Network
Wide部分输入手工特征工程的结果,如:年龄、历史记录
Deep部分是User、Item
最后结合到一起做出预测
Eg: Google Play
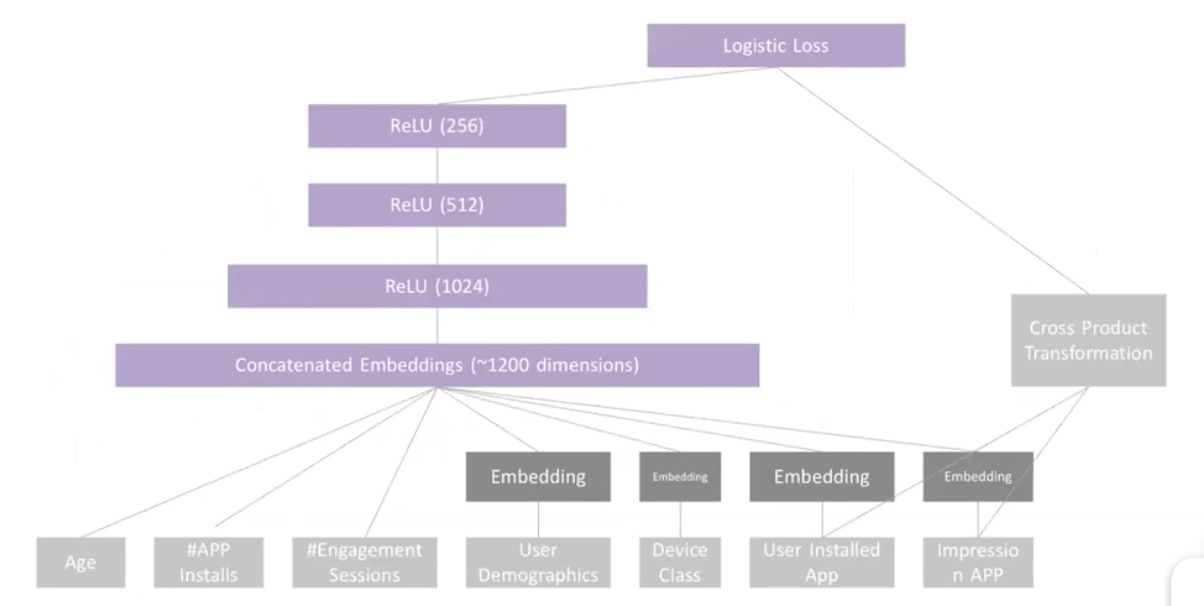
传统的 Factorization Machines
直接对产品的类型信息做One-Hot Encoding
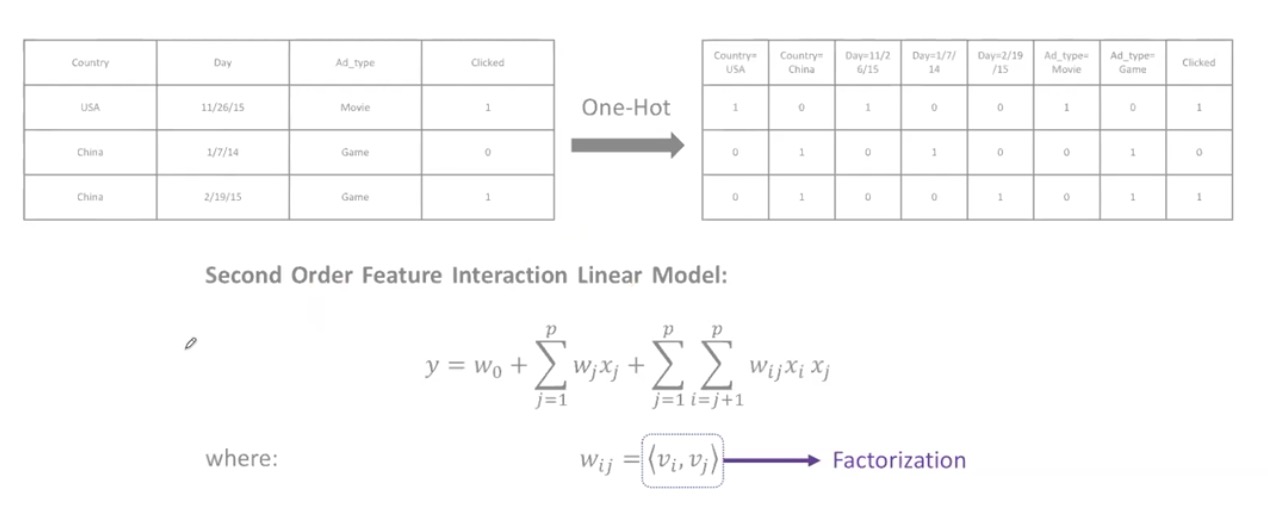
特征交叉 如性别=男,年龄=20 把对应的维相乘,数据过大是难处理
用矩阵分解的思想,wij变成<vi,vj>,其中vi,vj都是低维向量
变形版本:
Field-aware Factorization Machines
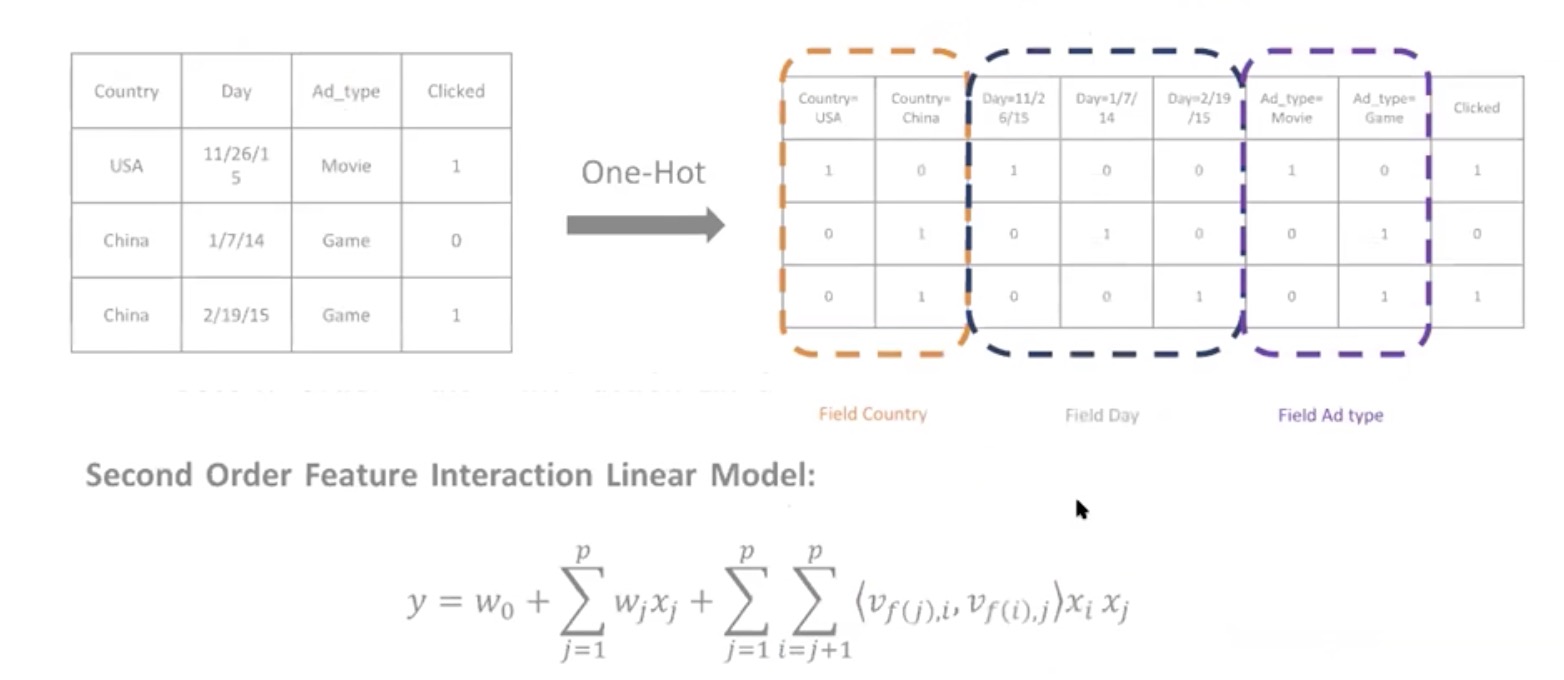
考虑特征是来自哪里的
每一个特征,与其他类别交叉时,有一个不一样的依赖向量
Deep Factorization Machines
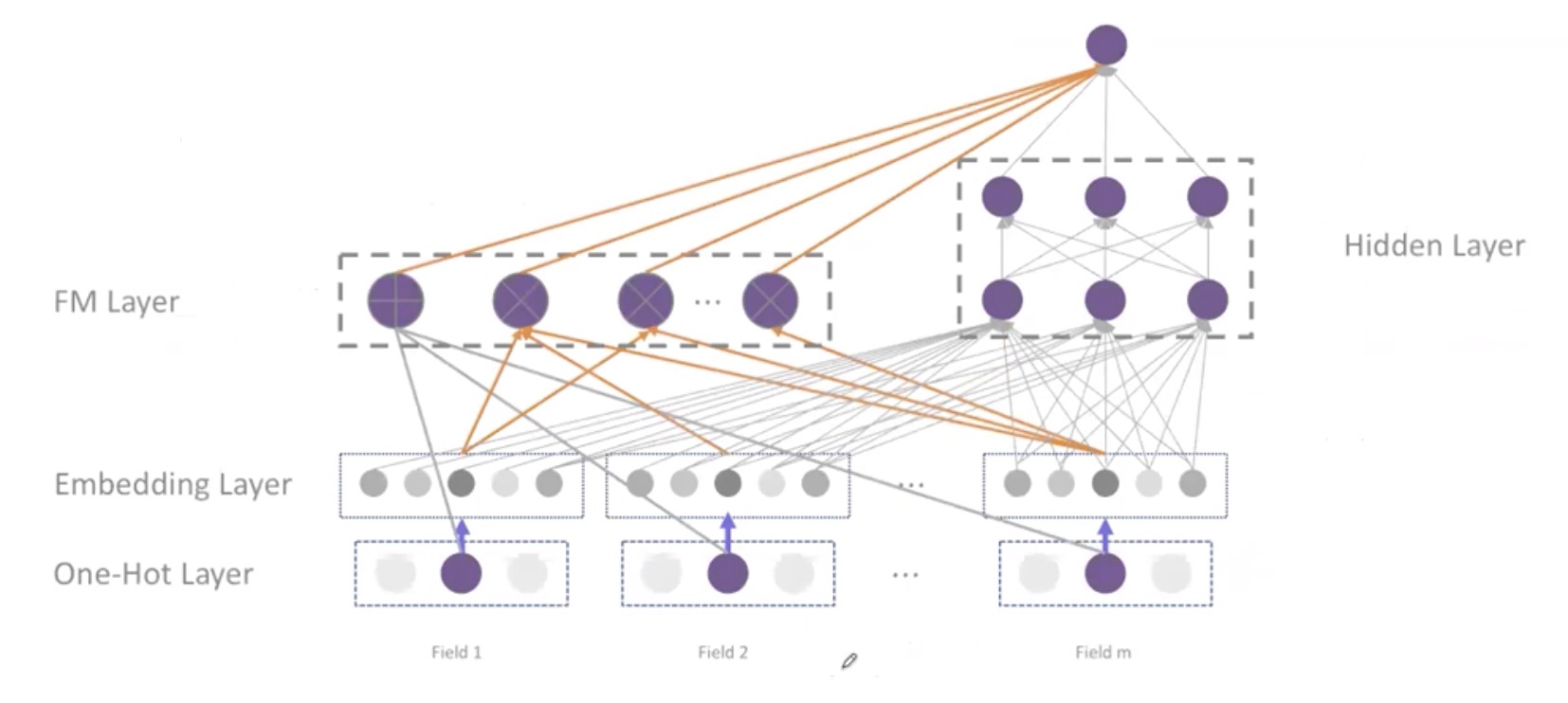
左侧:传统部分
每个种类做Embedding
为了实现交叉,两两做特征交叉
线性部分,求和(最左的+)
右侧:深度部分
美团的测试结果:
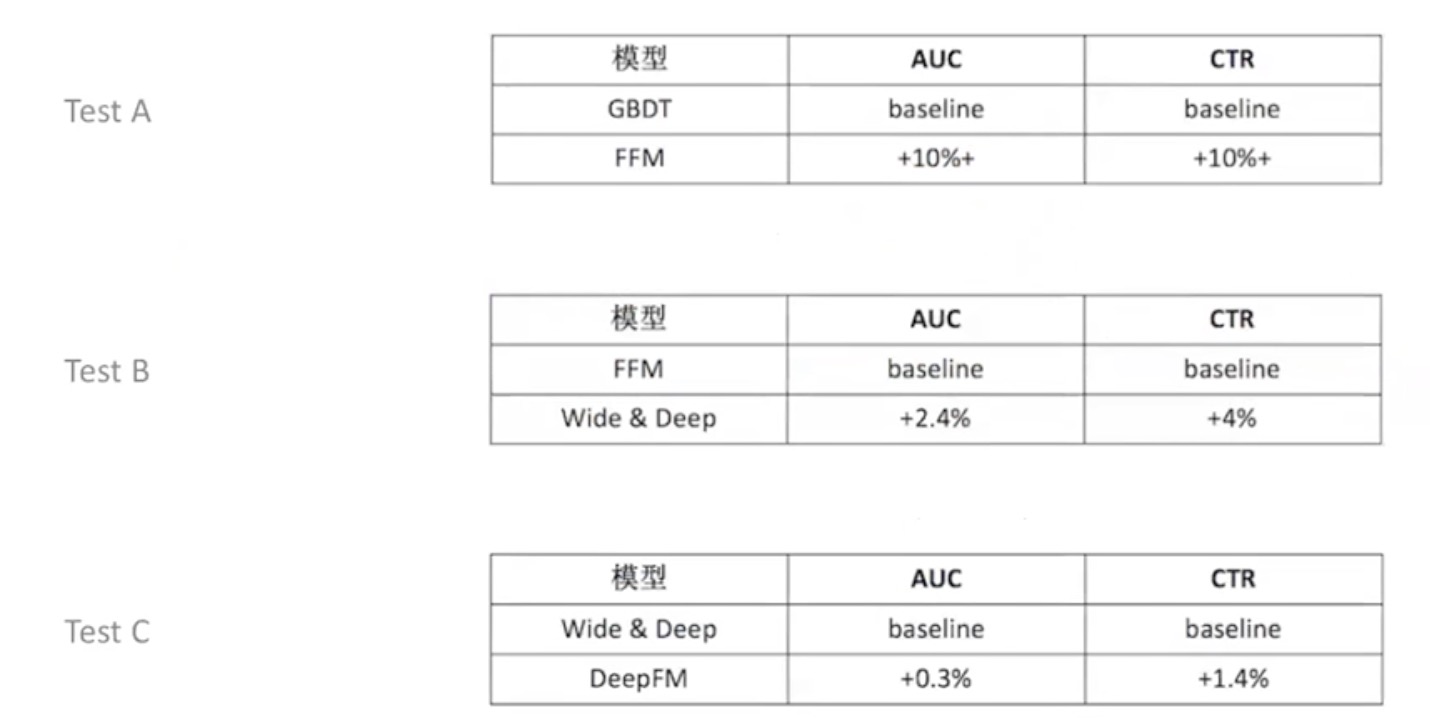
Wide & Deep 要做特征工程,DeepFM 做了一阶、二阶的特征交叉,同时用Deep神经网络做特征工程
Deep Cooperative Neural Network
卷积神经网络
涉及图片、文字时可参考
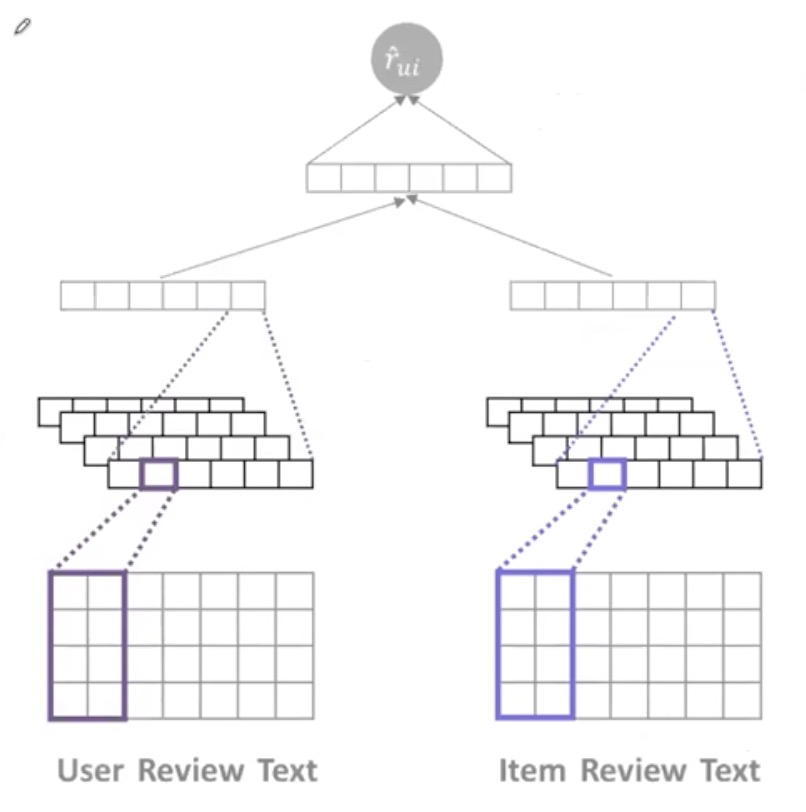
Word-Embedding 把每个单词映射成向量(Google : word2vec)
最后得到User记录的低维表示,Item描述的低维表示
Recurrent Neural Network
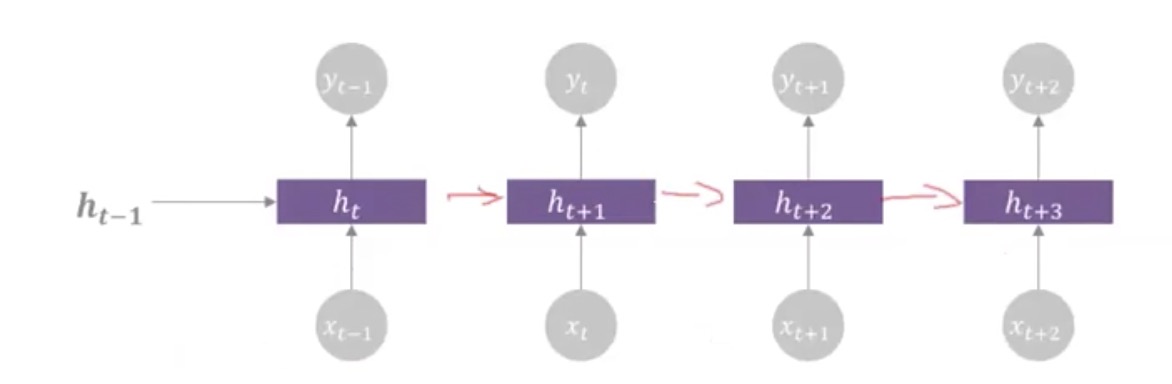
给一个input,映射成低维向量,输出output
同时反复自己迭代
可学习与时间有关的信息,如不需要login的网站上用户点击的行为
Session-based Recommendation with RNN
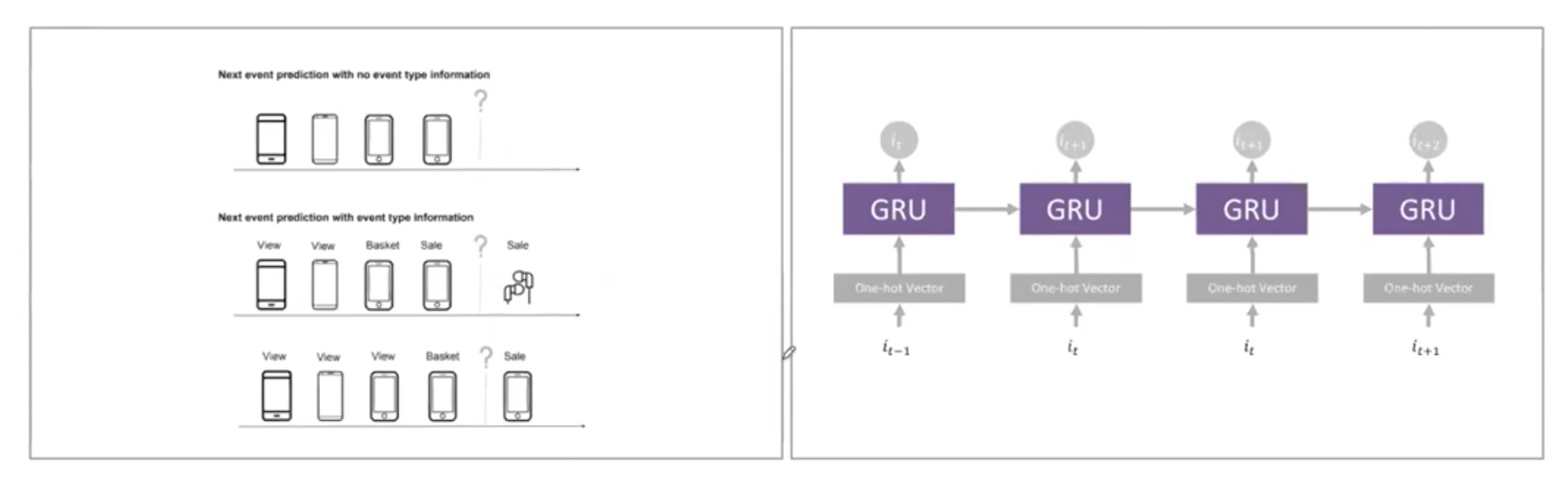
预测用户下一步行为
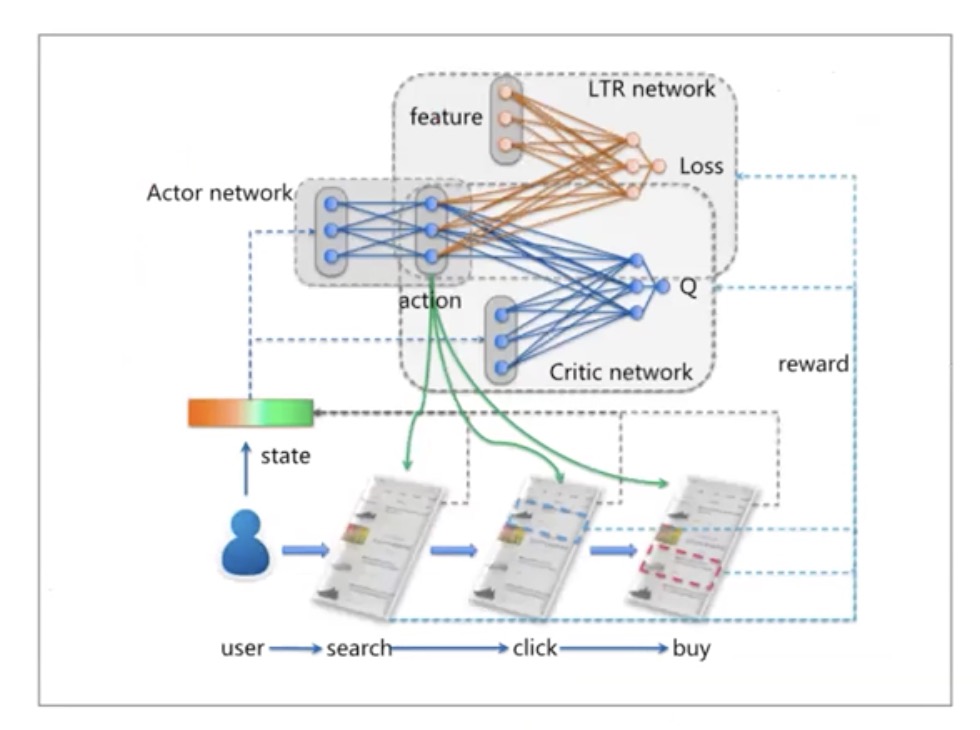
强化学习
因为用户行为随时在变化,传统推荐系统无法实时做出调整
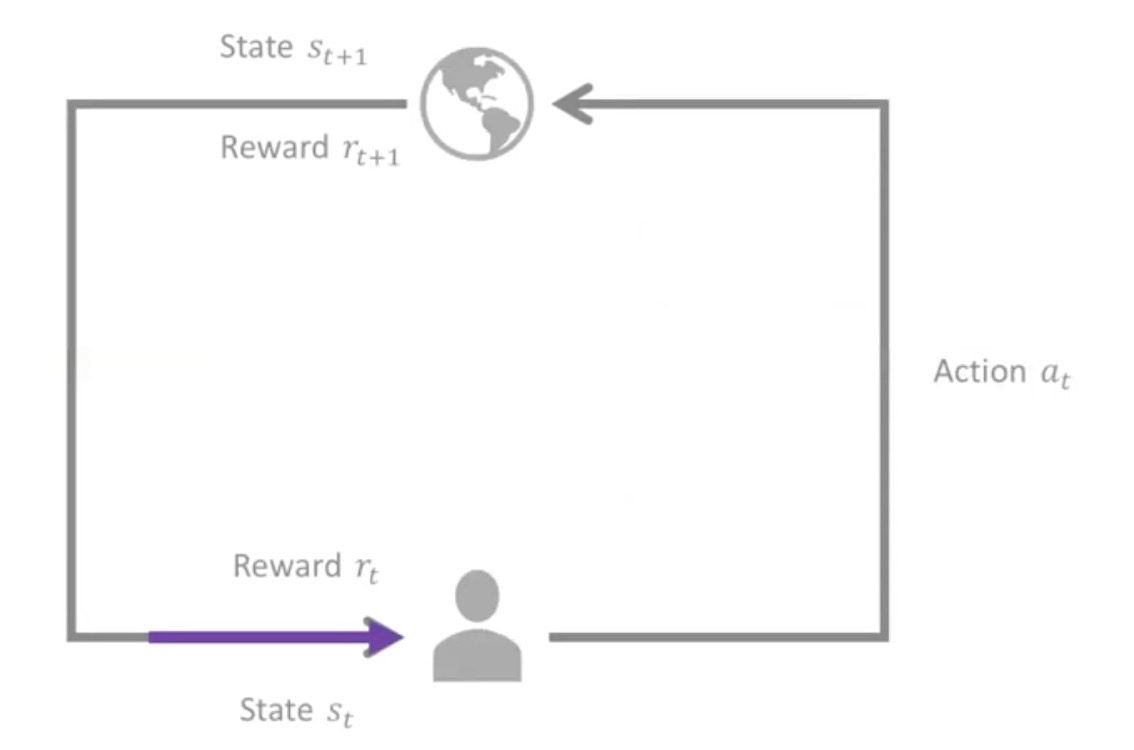
State可以是用户的点击行为
Reward可以是点击了推荐的产品
根据当前的State和Reward返回下一步Action
用户对Action做出反应,得到新的State和Reward
阿里的例子: